Tema 4 Contrastes de hipótesis paramétricos
Para que la estadística inferencial sea útil no solo necesitamos estimar un valor sino que además tendremos que tomar una decisión apoyada en los datos (muestras) que acepte o rechace alguna afirmación relativa al valor de un parámetro.
Ejemplo moluscos
Los responsables de salud pública del gobierno han determinado que el número medio de bacterias por cc en las aguas en las que se practica la recogida de moluscos para el consumo humano tiene que ser \(\leq 70\).
Tomamos una serie de muestras de agua de una zona, y hemos de decidir si podemos recoger moluscos.
Ejemplo routers
Una empresa de telecomunicaciones recibe una partida de 100 routers cada mes. El técnico que se encarga de la recepción del material tiene la orden de rechazar entera las partidas que contengan más de un 5% de unidades defectuosas.
El técnico, al no disponer de tiempo material para revisar todos los routers, toma la decisión de aceptar o rechazar la partida basándose en el análisis de una muestra aleatoria de unidades.
Estas afirmaciones reciben el nombre de hipótesis y el método estadístico de toma de una decisión sobre una hipótesis recibe el nombre de contraste de hipótesis.
En un contraste de hipótesis, se contrastan dos hipótesis alternativas: la hipótesis nula \(H_0\) y la hipótesis alternativa \(H_{1}\).
La
La
Si no obtenemos evidencia a favor de \(H_1\), no podemos rechazar \(H_0\) (diremos que aceptamos \(H_0\), pero es un abuso de lenguaje).
Ejemplo moluscos
Sea \(\mu\) el número medio de bacterias por cc de agua.
El contraste que nos planteamos es el siguiente: \[ \left\{\begin{array}{ll} H_{0}:\mu\leq 70\\ H_{1}:\mu>70 \end{array} \right. \]
La decisión que tomaremos se basará en algunas muestras de las que calcularemos la media muestral del número de bacterias por cc.
Si es bastante grande, lo consideraremos como una evidencia de \(H_1\), y si no, aceptaremos \(H_0\).
Ejemplo routers
Sea \(p\) la proporción de unidades defectuosas.
El contraste que nos planteamos es el siguiente: \[ \left\{\begin{array}{ll} H_{0}:p\leq 0.05\\ H_{1}:p>0.05 \end{array} \right. \] La decisión que tomemos se basará en las comprobaciones que realice el encargado de algunas unidades.
Calculará la proporción muestral de routers defectuosos. Si es bastante grande, lo consideraremos una evidencia de \(H_1\), y si no, aceptaremos \(H_0\).
4.1 Los contrastes de hipótesis
Hipótesis nula \(H_{0}\): es la hipótesis que “por defecto” aceptamos como verdadera, y que rechazamos si hay pruebas en contra,
Hipótesis alternativa \(H_{1}\): es la hipótesis contra la que contrastamos la hipótesis nula y que aceptamos cuando rechazamos la nula,
y generar una regla de decisión para rechazar o no la hipótesis nula a partir de la información contenida en una muestra.
En un juicio, tenemos que declarar a un acusado inocente o culpable.
O sea, se plantea el contraste siguiente: \[ \left\{\begin{array}{ll} H_{0}:\mbox{El acusado es inocente.}\\ H_{1}:\mbox{El acusado es culpable.} \end{array} \right. \]
Las pruebas serían los elementos de la muestra.
Si el jurado encuentra pruebas suficientemente incriminatorias, declara culpable al acusado (rechaza \(H_0\) en favor de \(H_1\)).
En caso contrario, si no las encuentra suficientemente incriminatorias, le declara no culpable (no rechaza \(H_0\))
Considerar no culpable \(\neq\) declarar inocente.
Las pruebas tienen que aportar evidencia de \(H_1\), lo que nos permitirá rechazar \(H_0\).
Es imposible encontrar evidencias de que \(\mu\) sea igual a un cierto valor \(\mu_0\). En cambio, sí que es puede hallar evidencias de que \(\mu > \mu_0\) , o de que \(\mu<\mu_0\), o que \(\mu\neq\mu_0\).
En este contexto:
\(H_1\) se define con \(>\), \(<\), o \(\neq\).
\(H_0\) se define con \(=\), \(\leq\), o \(\geq\).
\(H_1\) es la hipótesis de la que podemos hallar pruebas incriminatorias, \(H_0\) la que estamos dispuestos a aceptar si no hay pruebas en contra.
Ejemplo
Queremos decidir si la media es más pequeña que 2 o no: \[ \left\{\begin{array}{ll} H_{0}:\mu= 2\ (\mbox{o } \mu \geq 2),\\ H_{1}:\mu< 2. \end{array} \right. \]
Ejemplo
Queremos decidir si la media es igual o diferente de 5 \[ \left\{\begin{array}{ll} H_{0}:\mu= 5\\ H_{1}:\mu\neq 5 \end{array} \right. \]
Ejemplo
Queremos dar la alerta de desastre natural inminente y poner a la población a salvo si la media de cierta variable meteorológica (temperatura, presión,…) toma el valor \(\mu_0\): \[ \left\{\begin{array}{ll} H_{0}:\mu= \mu_0\\ H_{1}:\mu\neq \mu_0 \end{array} \right. \]
4.1.1 Tipos de hipótesis alternativas
Hipótesis unilateral (one-sided, también de una cola, one-tailed): \(H: \theta>\theta_{0}\), \(H: \theta<\theta_0\).
Hipótesis bilateral (two-sided, también de dos colas, two-tailed): \(H: \theta\neq\theta_0\)
Los tests suelen tomar el nombre de la hipótesis alternativa: test unilateral, test de dos colas, etc.
4.1.2 Tipos de errores
La tabla siguiente resume los 4 casos que se pueden dar dependiendo de la decisión tomada:
| Decisión/Realidad | \(H_{0}\) cierta | \(H_{0}\) falsa |
|---|---|---|
| Aceptar \(H_{0}\) | Decisión correcta | Error Tipo II |
| Probabilidad=\(1-\alpha\) | Probabilidad=\(\beta\) | |
| Rechazar \(H_{0}\) | Error Tipo I | Decisión correcta |
| Probabilidad=\(\alpha\) | Probabilidad=\(1-\beta\) |
Error de Tipo I: rechazar \(H_0\) cuando es cierta. La probabilidad de cometerlo es: \[P(\mbox{Error Tipo I})=P(\mbox{Rechazar } H_{0}\mid H_{0} \mbox{ cierta})=\alpha,\] donde \(\alpha\) es el nivel de significación del contraste.
Error de Tipo II: aceptar \(H_0\) cuando es falsa. La probabilidad de cometerlo es: \[P(\mbox{Error Tipo II})=P(\mbox{Aceptar } H_{0}| H_{0} \mbox{ falsa})=\beta,\] donde \(1-\beta=P(\mbox{Rechazar } H_{0}|H_{0} \mbox{ falsa})\) es la potencia del contraste.
En un juicio, se declarar un acusado inocente o culpable.
El error de Tipo I sería declarar culpable a un inocente.
El Error de Tipo II sería declarar no culpable a un culpable.
Es más grave desde el punto de vista ético cometer un error tipo I ya que es peor castigar a un inocente que perdonar a un culpable. Por tanto, conviene minimizarlo.
En el desastre natural, damos la alerta si \(\mu\) se acerca a cierto valor \(\mu_0\).
El error de Tipo I sería no dar la alarma cuando el desastre natural ocurre (muertes varias).
El Error de Tipo II sería dar la alarma a pesar de que no haya desastre natural (falsa alarma).
Lo más conveniente es encontrar una regla de rechazo de \(H_{0}\) que tenga poca probabilidad de error de tipo I, \(\alpha\).
Pero también querríamos minimizar la probabilidad de error de tipo II, \(\beta\).
¿Qué se suele hacer?
- Encontrar una regla de decisión para a un \(\alpha\) máximo fijado.
- Después, si es posible, controlar la tamaño \(n\) de la muestra para minimizar \(\beta\).
4.1.3 Terminología
En un contraste de hipótesis, tenemos los siguientes conceptos:
Estadístico de contraste: es una variable aleatoria función de la muestra que nos permite definir una regla de rechazo de \(H_{0}\).
Nivel de significación \(\alpha\): la probabilidad de error de tipo I.
Región crítica o de rechazo: zona o región de números reales donde se verifica que si el estadístico de contraste pertenece a la región crítica, entonces rechazamos \(H_{0}\).
Región de aceptación: zona o región complementaria de la región crítica.
Intervalo de confianza del \((1-\alpha)\cdot 100\%\): intervalo de confianza para el parámetro poblacional del contraste. Es equivalente afirmar que el estadístico de contraste pertenece a la región de aceptación que afirmar que el parámetro del contraste pertenece al intervalo de confianza del contraste.
4.2 Contrastes de hipótesis para el parámetro \(\mu\) de una variable normal con \(\sigma\) conocida
Sea \(X\) una variable aleatoria \(N(\mu,\sigma)\) con \(\mu\) desconocida y \(\sigma\) conocida.
Sea \(X_{1},\ldots,X_{n}\) una m.a.s. de \(X\) de tamaño \(n\).
Nos planteamos el contraste siguiente: \[ \left\{\begin{array}{l} H_{0}:\mu=\mu_{0}\\ H_{1}:\mu >\mu_0 \end{array} \right. \] De cara a hallar la región de rechazo, pensemos que tenemos que rechazar \(H_0\) en favor de \(H_1\) si \(\overline{X}\) es “bastante más grande” que \(\mu_0\).
Si \(H_0\) es verdadera,
\[ Z=\frac{\overline{X}-\mu_{0}}{\frac{\sigma}{\sqrt{n}}}\sim N(0,1) \]
Entonces, la regla consistirá en rechazar \(H_{0}\) si el estadístico de contraste \(Z\) es mayor que un cierto umbral, que determinaremos con \(\alpha\), el nivell de significación del contraste o el error tipo I.
De cara a hallar la región de rechazo, queremos que se cumpla lo siguiente: \[ \begin{array}{l} \alpha =P(\mbox{rechazar } H_{0}| H_{0} \mbox{ cierta })=P(Z>\mbox{umbral })\\ \quad \Longrightarrow 1-\alpha= P(Z\leq \mbox{umbral })\Longrightarrow \mbox{umbral }=z_{1-\alpha}. \end{array} \] Por tanto, para que el nivel de significación del contraste sea \(\alpha\), la regla de rechazo tiene que ser: \(Z>z_{1-\alpha}\)
En resumen, rechazamos \(H_0\) si \(\dfrac{\overline{X}-\mu_{0}}{\sigma/\sqrt{n}}>z_{1-\alpha}\).
Gráfico de la región de rechazo. Las abscisas o coordenadas \(x\) de la zona en azul serían los valores \(z\) para los que rechazaríamos la hipótesis nula \(H_0\):
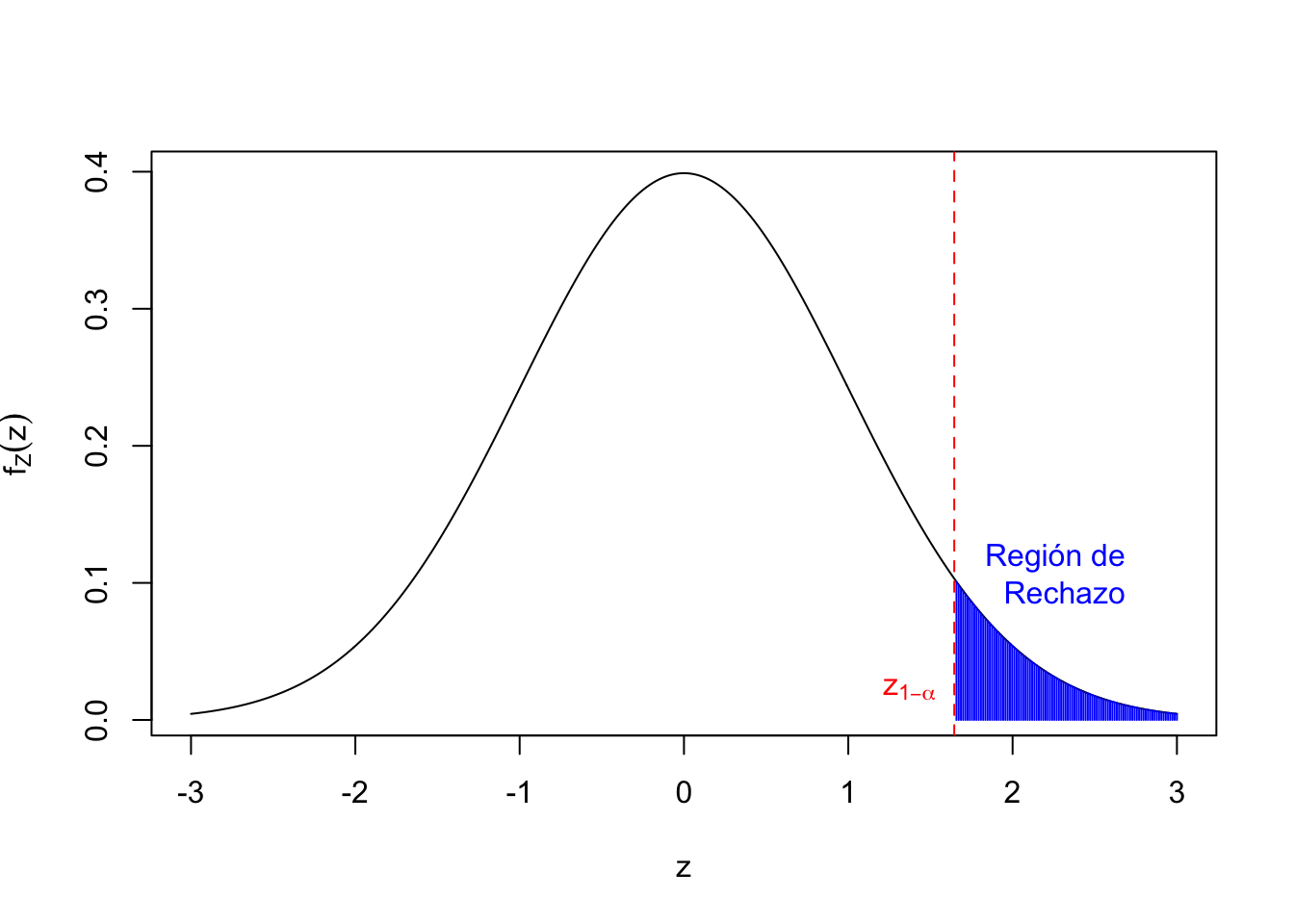
El contraste anterior tiene como:
Estadístico de contraste: \(Z=\dfrac{\overline{X}-\mu_0}{\frac{\sigma}{\sqrt{n}}}\).
Región crítica: \((z_{1-\alpha},\infty)\).
Región de aceptación: \((-\infty,z_{1-\alpha}]\).
Regla de decisión: rechazar \(H_0\) si \(Z>z_{1-\alpha}\).
Intervalo de confianza: \[ \begin{array}{l} Z< z_{1-\alpha}\Longleftrightarrow \dfrac{\overline{X}-\mu_0}{\frac{\sigma}{\sqrt{n}}}< z_{1-\alpha} \Longleftrightarrow \mu_0> \overline{X}-z_{1-\alpha}\cdot\frac{\sigma}{\sqrt{n}}\\ \qquad\quad\Longleftrightarrow \mu_0\in {\Big(\overline{X}-z_{1-\alpha}\cdot\frac{\sigma}{\sqrt{n}},\infty\Big)} \end{array} \]
Regla de decisión II: rechazar \(H_0\) si el \(\mu_0\) contrastado no pertenece al intervalo de confianza.
Ejercicio
Sea \(X\) una población normal con \(\sigma=1.8\). Queremos hacer el contraste \[ \left\{\begin{array}{l} H_0:\mu=20\\ H_1:\mu>20 \end{array} \right. \] con un nivel de significación de \(0.05\).
Tomamos una m.a.s. de \(n=25\) observaciones y obtenemos \(\overline{x}=20.25\).
¿Qué decidimos?
Tenemos los siguientes valores: \(\alpha=0.05\), \(\sigma=1.8\), \(n=25\), \(\overline{x}=20.25\).
El Estadístico de contraste valdrá \(Z=\dfrac{\overline{X}-20}{\frac{1.8}{\sqrt{25}}}=0.694.\)
La Región crítica será \((z_{1-0.05},\infty)=(1.645,\infty)\).
Decisión: Como que \(0.694<1.645\), no pertenece a la región crítica y por tanto no tenemos suficientes evidencias para rechazar \(H_0\).
El Intervalo de confianza será: \[ \Big(\overline{X}-z_{1-\alpha}\cdot\frac{\sigma}{\sqrt{n}},\infty\Big)=(19.658,\infty) \] Decisión II: Como \(\mu_0=20\) pertenece al intervalo de confianza, no podemos rechazar \(H_0\).
Sea \(X\) una v.a. \(N(\mu,\sigma)\) con \(\mu\) desconocida y \(\sigma\) conocida
Sea \(X_1,\ldots,X_{n}\) una m.a.s. de \(X\) de tamaño \(n\)
Nos planteamos el contraste \[ \left\{\begin{array}{l} H_0:\mu=\mu_0\\ H_1:\mu\ <\ \mu_0 \end{array} \right. \] donde vamos a rechazar \(H_0\) si \(Z=\dfrac{\overline{X}-\mu_0}{{\sigma}/{\sqrt{n}}}\) es inferior a un cierto umbral, que determinaremos con \(\alpha\).
Queremos que el Error Tipo I sea \(\alpha\): \[ \alpha =P(\mbox{rechazar } H_0| H_0 \mbox{ cierta}) =P(Z<\mbox{umbral })\Longrightarrow \mbox{umbral }=z_{\alpha}, \] por lo tanto, para que el nivel de significación del contraste Sea \(\alpha\), la regla de rechazo tiene que ser \(Z<z_{\alpha}\).
La Región crítica es \((-\infty,z_{\alpha})\).
En resumen, rechazamos \(H_0\) si \(\dfrac{\overline{X}-\mu_{0}}{\sigma/\sqrt{n}} < z_{\alpha}=-z_{1-\alpha}\).
Gráfico de la región de rechazo. Las abscisas o coordenadas \(x\) de la zona en azul serían los valores \(z\) para los que rechazaríamos la hipótesis nula \(H_0\):

El contraste anterior tiene como:
Estadístico de contraste: \(Z=\dfrac{\overline{X}-\mu_0}{\frac{\sigma}{\sqrt{n}}}\).
Región crítica: \((-\infty,-z_{1-\alpha})\).
Región de aceptación: \([-z_{1-\alpha},\infty)\).
Regla de decisión: rechazar \(H_0\) si \(Z < -z_{1-\alpha}\).
Intervalo de confianza: \[ \begin{array}{l} Z> -z_{1-\alpha}\Longleftrightarrow \dfrac{\overline{X}-\mu_0}{\frac{\sigma}{\sqrt{n}}}> -z_{1-\alpha} \Longleftrightarrow \mu_0< \overline{X}+z_{1-\alpha}\cdot\frac{\sigma}{\sqrt{n}}\\ \qquad\quad\Longleftrightarrow \mu_0\in {\Big(-\infty,\overline{X}+z_{1-\alpha}\cdot\frac{\sigma}{\sqrt{n}}\Big)} \end{array} \]
Regla de decisión II: rechazar \(H_0\) si el \(\mu_0\) contrastado no pertenece al intervalo de confianza.
Sea \(X\) una v.a. \(N(\mu,\sigma)\) con \(\mu\) desconocida y \(\sigma\) conocida
Sea \(X_1,\ldots,X_{n}\) una m.a.s. de \(X\) de tamaño \(n\)
Consideremos ahora el contraste \[ \left\{\begin{array}{l} H_0:\mu=\mu_0\\ H_1:\mu\ \neq\ \mu_0 \end{array} \right. \]
Rechazar \(H_0\) si \(Z=\dfrac{\overline{X}-\mu_0}{{\sigma}/{\sqrt{n}}}\) está a bastante lejos de de 0, y la determinaremos con el valor de \(\alpha\)
Queremos como antes que el Error Tipo I sea \(\alpha\): \[ \begin{array}{rl} \alpha & =P(\mbox{rechazar } H_0| H_0 \mbox{ cierta }) =P(Z<-\mbox{umbral }\mbox{ o }Z>\mbox{umbral })\\ & =P(Z<-\mbox{umbral })\!+\!P(Z>\mbox{umbral }) = 2P(Z>\mbox{umbral }) \\ &= 2(1-P(Z<\mbox{umbral })) \Longrightarrow P(Z<\mbox{umbral })=1-\dfrac{\alpha}2,\\ & \qquad \Longrightarrow \mbox{umbral }=z_{1-\frac{\alpha}2}. \end{array} \]
Ahora para que el nivel de significación del contraste sea \(\alpha\), la regla de rechazo tiene que ser \[ Z<-z_{1-\frac{\alpha}2}=z_{\frac{\alpha}2}\mbox{ o }Z>z_{1-\frac{\alpha}2}. \] La región crítica es \((-\infty,z_{\frac\alpha2})\cup (z_{1-\frac{\alpha}2},\infty).\)
Gráfico de la región de rechazo. Las abscisas o coordenadas \(x\) de la zona en azul serían los valores \(z\) para los que rechazaríamos la hipótesis nula \(H_0\):
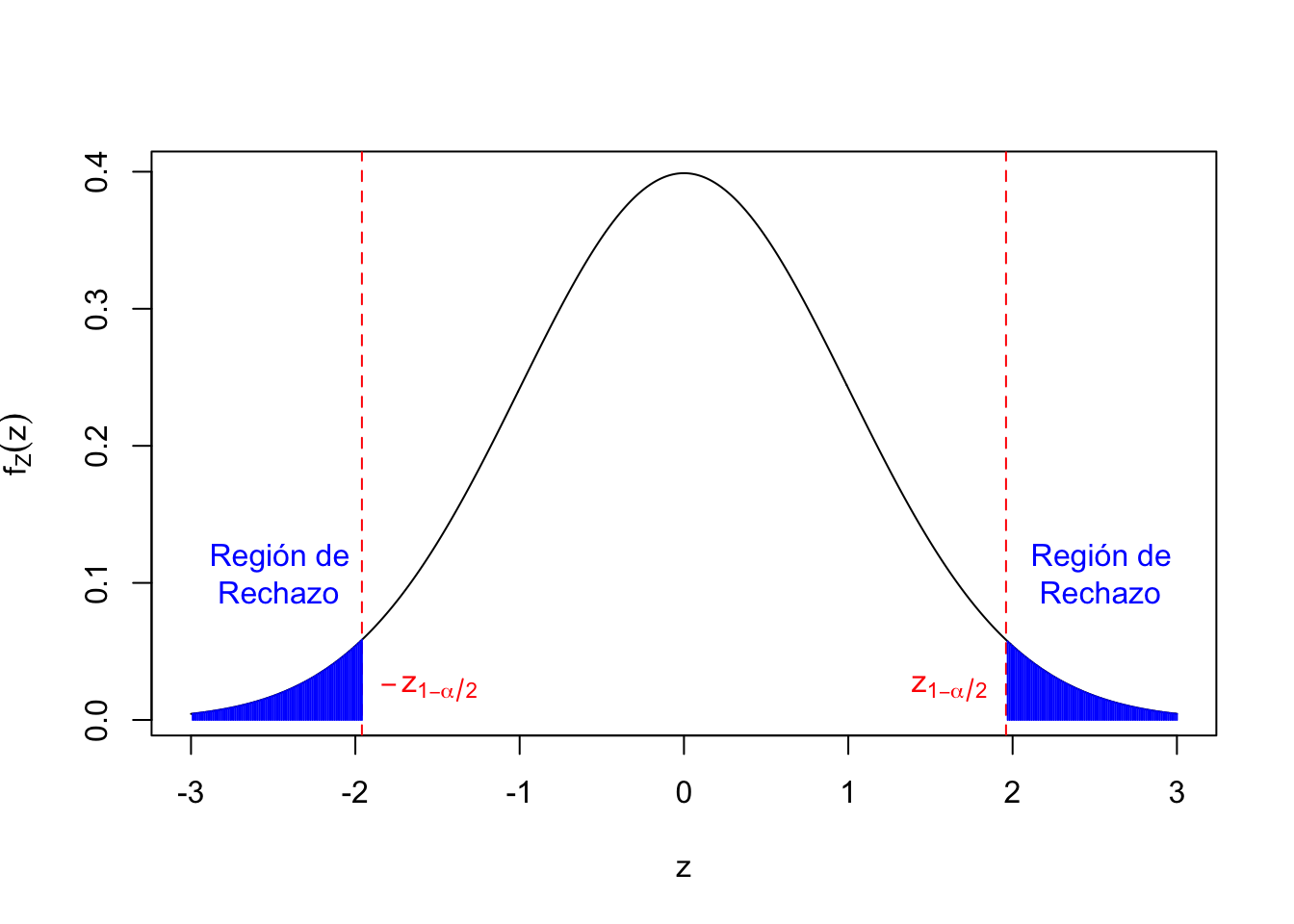
Seguidamente, calculemos el Intervalo de confianza para el contraste anterior: \[ \begin{array}{l} -z_{1-\frac{\alpha}2} < Z < z_{1-\frac{\alpha}2}\Longleftrightarrow -z_{1-\frac{\alpha}2} < \dfrac{\overline{X}-\mu_0}{\frac{\sigma}{\sqrt{n}}}< z_{1-\frac{\alpha}2}\\ \qquad\Longleftrightarrow -z_{1-\frac{\alpha}2}\frac{\sigma}{\sqrt{n}}< \overline{X}-\mu_0< z_{1-\frac{\alpha}2}\frac{\sigma}{\sqrt{n}}\\\qquad \Longleftrightarrow \overline{X}-z_{1-\frac\alpha2}\frac{\sigma}{\sqrt{n}}< \mu_0< \overline{X}+z_{1-\frac{\alpha}2}\frac{\sigma}{\sqrt{n}} \\ \qquad\Longleftrightarrow\mu_0\in \Big(\overline{X}-z_{1-\frac\alpha2}\frac{\sigma}{\sqrt{n}},\overline{X}+z_{1-\frac{\alpha}2}\frac{\sigma}{\sqrt{n}}\Big) \end{array} \]
Ejercicio
Sea \(X\) una población normal con \(\sigma=1.8\). Queremos realizar el contraste \[ \left\{\begin{array}{l} H_0:\mu=20\\ H_1:\mu\neq 20 \end{array} \right. \] con un nivel de significación de \(0.05\).
Tomamos una m.a.s. de \(n=25\) observaciones y obtenemos \(\overline{x}=20.5\).
¿Qué decidimos?
Tenemos los valores siguientes: \(\alpha=0.05\), \(\sigma=1.8\), \(n=25\), \(\overline{x}=20.5\).
El Estadístico de contraste vale \(Z= \dfrac{\overline{X}-20}{\frac{1.8}{\sqrt{25}}}=1.389.\)
La Región crítica será: \((-\infty,z_{0.025}[\cup ]z_{0.975},\infty)\)=\((-\infty,-1.96)\cup (1.96,\infty)\).
El Intervalo de confianza será: \(\left(20.5-1.96 \frac{1.8}{\sqrt{25}}, 20.5+1.96 \frac{1.8}{\sqrt{25}}\right) = (19.794,21.206)\).
Decisión: No tenemos evidencias suficientes para rechazar \(H_0\) ya que, por un lado, el estadístico de contraste no pertenece a la región crítica y, por otro, el valor \(\mu_0 =20\) pertenece al intervalo de confianza.
4.2.1 El \(p\)-valor
El \(p\)-valor o valor crítico (\(p\)-value) de un contraste es la probabilidad que, si \(H_0\) es verdadera, el estadístico de contraste tome un valor tan extremo o más que el que se ha observado.
Consideremos por ejemplo un contraste del tipo: \[ \left\{\begin{array}{l} H_0:\mu=\mu_0\\ H_1:\mu\ >\ \mu_0. \end{array} \right. \] Si el estadístico \(Z\) tiene el valor \(z_0\), el \(p\)-valor será: \[ \mbox{$p$-valor}=P(Z\ \geq\ z_0). \]
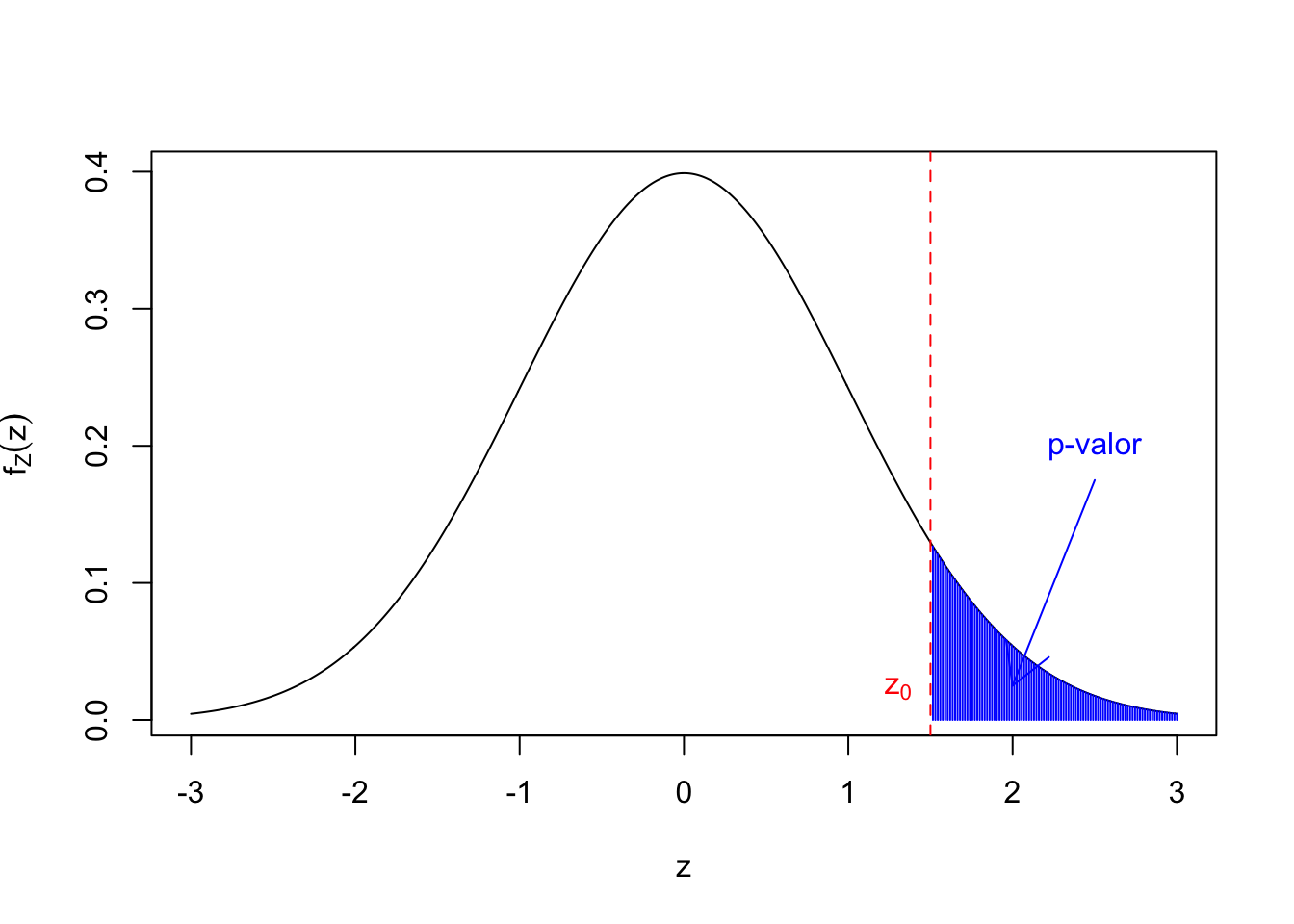
Para el contraste:
\[ \left\{\begin{array}{l} H_0:\mu=\mu_0\\ H_1:\mu\ <\ \mu_0. \end{array} \right. \] Si el estadístico \(Z\) tiene el valor \(z_0\), el \(p\)-valor será: \[ \mbox{$p$-valor}=P(Z\ \leq\ z_0). \]
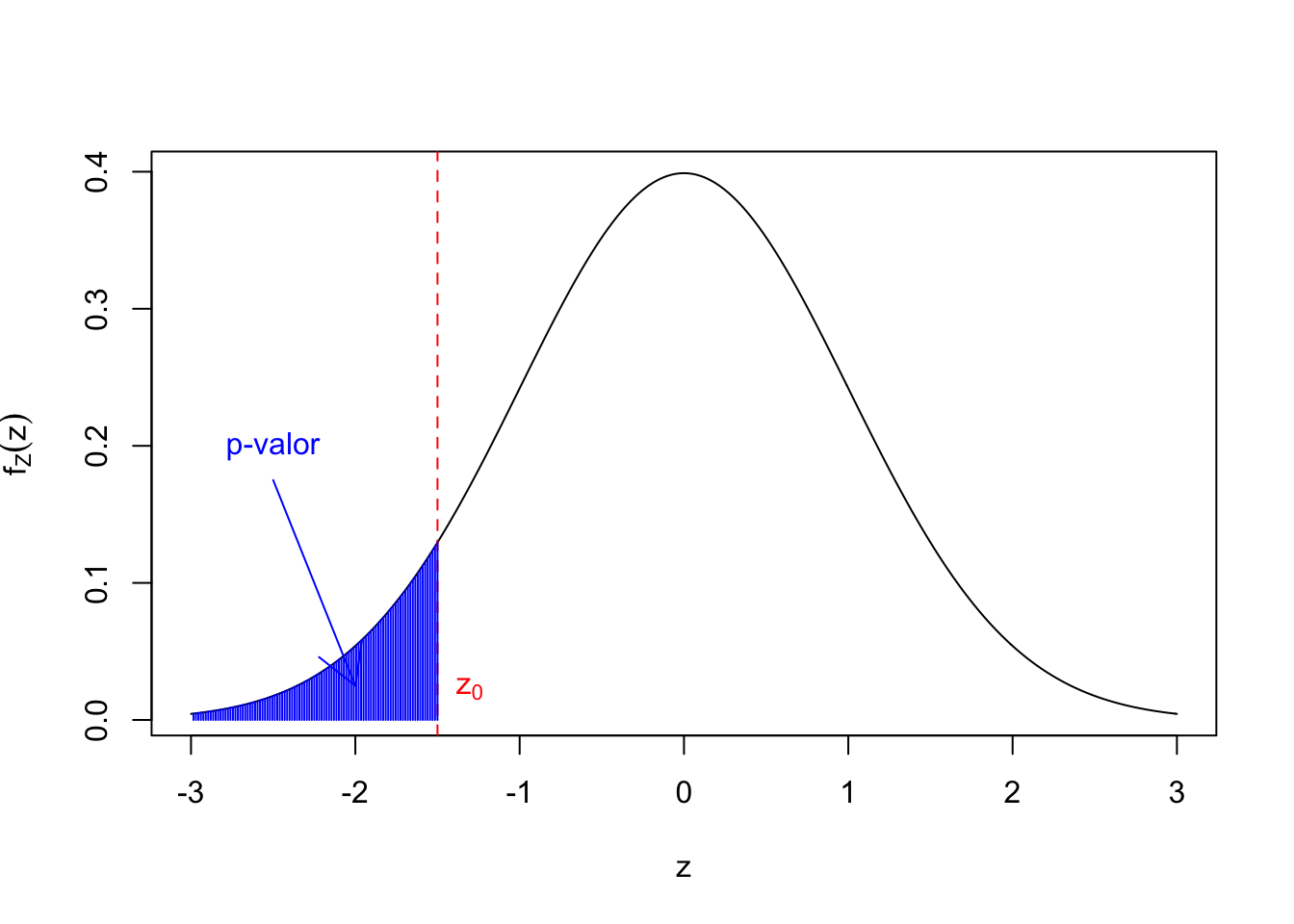
Si ahora consideramos el contraste \[ \left\{\begin{array}{l} H_0:\mu=\mu_0\\ H_1:\mu\ \neq\ \mu_0 \end{array} \right. \] y si el estadístico \(Z\) ha dado \(z_0\), el \(p\)-valor será: \[ \mbox{$p$-valor} =2 \cdot \min\{P(Z \leq -|z_0|),P(Z \geq |z_0|) =2\cdot P(Z \geq |z_0|) \]
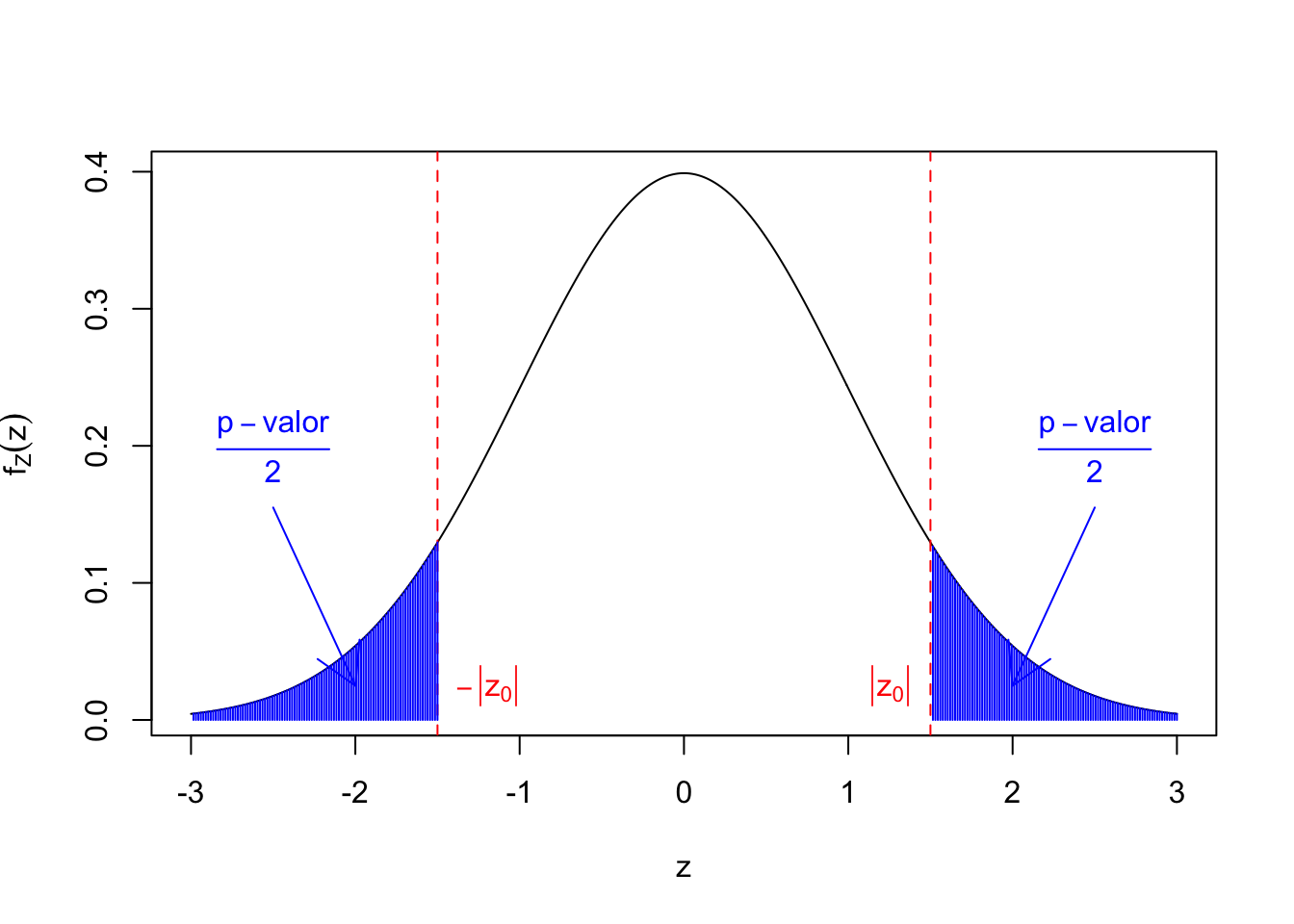
El \(p\)-valor o valor crítico (\(p\)-value) de un contraste es la probabilidad que, si \(H_0\) es verdadera, el estadístico de contraste tome un valor tan extremo o más que el que se ha observado.
Es una medida inversa de la fuerza de las pruebas o evidencias que hay en contra de \(H_1\): si \(H_0\) es verdadera, cuanto más pequeño sea el \(p\)-valor, más improbable es observar lo que hemos observado.
En consecuencia, cuanto más pequeño sea el \(p\)-valor, con más fuerza podemos rechazar \(H_0\).
Supongamos, por ejemplo, que hemos obtenido un \(p\)-valor de \(0.03\):
Significa que la probabilidad de que, si \(H_0\) es verdadera, el estadístico de contraste tome un valor tan extremo o más que el que ha tomado, es 0.03 (pequeño: evidencia de que \(H_0\) es falsa.)
No significa:
La probabilidad que \(H_0\) Sea verdadera es \(0.03\)
\(H_0\) es verdadera un 3% de les veces
En un contraste con nivel de significación \(\alpha\),
rechazamos \(H_0\) si \(p\)-valor \(<\alpha\).
aceptamos \(H_0\) si \(\alpha\leq p\)-valor.
Si consideramos por ejemplo un contraste del tipo: \[ \left\{\begin{array}{l} H_0:\mu=\mu_0\\ H_1:\mu> \mu_0 \end{array} \right. \]
y suponemos que el estadístico \(Z\) vale \(z_0\). El \(p\)-valor es \(P(Z \geq z_0)\). Entonces:
Rechazamos \(H_0\) \(\Longleftrightarrow z_0>z_{1-\alpha},\),
O, dicho de otra forma, \[\mbox{$p$-valor}=P(Z \geq z_0)<P(Z\geq z_{1-\alpha})=1-(1-\alpha)=\alpha.\]
Si ahora consideramos un contraste del tipo: \[ \left\{\begin{array}{l} H_0:\mu=\mu_0\\ H_1:\mu < \mu_0 \end{array} \right. \]
y suponemos que el estadístico \(Z\) vale \(z_0\). El \(p\)-valor es \(P(Z \leq z_0)\). Entonces:
Rechazamos \(H_0\) \(\Longleftrightarrow z_0 < z_{\alpha},\)
O, dicho de otra forma, \[\mbox{$p$-valor}=P(Z \leq z_0) < P(Z\leq z_{\alpha})=\alpha.\]
Por último, supongamos que el contraste es del tipo: \[ \left\{\begin{array}{l} H_0:\mu=\mu_0\\ H_1:\mu \neq \mu_0 \end{array} \right. \] y que el estadístico \(Z\) vale \(z_0>0\). El \(p\)-valor es \(2P(Z \geq |z_0|)\). Entonces:
Rechazamos \(H_0 \Longleftrightarrow |z_0|>z_{1-\frac{\alpha}{2}}\),
O, dicho de otra forma, \[ \mbox{$p$-valor}=2P(Z \geq |z_0|)<2P(Z\geq z_{1-\frac{\alpha}2})=2\left(1-\left(1-\frac{\alpha}2\right)\right)=\alpha. \]
El \(p\)-valor de un contraste es:
El nivel de significación \(\alpha\) más pequeño para el que rechazamos la hipótesis nula.
El nivel de significación \(\alpha\) más grande para el que aceptaríamos la hipótesis nula.
La probabilidad mínima de error de Tipo I que permitimos si rechazamos la hipótesis nula con el valor del estadístico de contraste obtenido.
La probabilidad máxima de error de Tipo I que permitimos si aceptamos la hipótesis nula con el valor del estadístico de contraste obtenido.
Si no establecemos un nivel de significación \(\alpha\), entonces
Aceptamos \(H_0\) si el \(p\)-valor es “grande” (\(\geq 0.1\)).
Rechazamos \(H_0\) si el \(p\)-valor es “pequeño” (\(<0.05\)). En este caso, el \(p\)-valor es:
- Significativo si es \(< 0.05\) (En
R, se simboliza con un asterisco,*). - Fuertemente significativo si es \(<0.01\) (En
R, se simboliza con dos asteriscos,**). - Muy significativo si es \(<0.001\) (En
R, se simboliza con tres asteriscos,***).
- Significativo si es \(< 0.05\) (En
Si el \(p\)-valor está entre \(0.05\) y \(0.1\) y no tenemos nivel de significación, se requieren estudios posteriores para tomar una decisión.
Es la denominada zona crepuscular, o twilight zone.
Ejercicio
Sea \(X\) una población normal con \(\sigma=1.8\). Queremos hacer el contraste \[ \left\{\begin{array}{l} H_0:\mu=20,\\ H_1:\mu>20. \end{array} \right. \]
Tomamos una m.a.s. de \(n=25\) observaciones y obtenemos \(\overline{x}=20.25\).
¿Qué decidimos?
Como no nos dan el nivel de significación \(\alpha\), calcularemos el \(p\)-valor.
Si calculamos el estadístico de contraste, obtenemos \(z_0= \dfrac{\overline{X}-20}{\frac{1.8}{\sqrt{25}}}=\dfrac{20.25-20}{\frac{1.8}{\sqrt{25}}}=0.694.\)
El \(p\)-valor valdrá: \(p =P(Z\geq 0.694)= 0.244 > 0.1\) grande.
La decisión que tomamos por consiguiente es que no tenemos evidencias suficientes para rechazar \(H_0\).
Ejercicio
Sea \(X\) una población normal con \(\sigma=1.8\). Queremos hacer el contraste \[ \left\{\begin{array}{l} H_0:\mu=20\\ H_1:\mu>20 \end{array} \right. \]
Tomamos una m.a.s. de \(n=25\) observaciones y obtenemos \(\overline{x}=20.75\).
¿Qué decidimos?
El estadístico de contraste será \(Z= \dfrac{\overline{X}-20}{\frac{1.8}{\sqrt{25}}}= \dfrac{20.75-20}{\frac{1.8}{\sqrt{25}}}=2.083.\)
El \(p\)-valor será: \(P(Z\geq 2.083)=0.019\) pequeño.
En este caso la decisión será rechazar \(H_0\) ya que tenemos suficientes evidencias para hacerlo.
Si conocemos el nivel de significación \(\alpha\), la decisión que tomemos en un contraste se puede basar en:
la región crítica: si el estadístico de contraste cae dentro de la región crítica para al nivel de significación \(\alpha\), rechazamos \(H_0\).
el intervalo de confianza: si el parámetro poblacional a contrastar cae dentro del intervalo de confianza para el nivel \((1-\alpha)\cdot 100\%\) de confianza, aceptamos \(H_0\).
el \(p\)-valor: si el \(p\)-valor es más pequeño que el nivel de significación \(\alpha\), rechazamos \(H_0\).
Si desconocemos el nivel de significación \(\alpha\), la decisión que tomemos en un contraste se puede basar en:
- el \(p\)-valor: Si el \(p\)-valor es pequeño, rechazamos \(H_0\), y si es grande, la aceptamos.
4.2.2 El método de los seis pasos (caso de conocer \(\alpha\))
Establecer la hipótesis nula \(H_0\) y la hipótesis alternativa \(H_1\).
Fijar un nivel de significación \(\alpha\).
Seleccionar el estadístico de contraste apropiado.
Calcular el valor del estadístico de contraste a partir de les datos muestrales.
Calcular el \(p\)-valor del contraste.
Decisión: rechazar \(H_0\) en favor de \(H_1\) si el \(p\)-valor es más pequeño que \(\alpha\); en caso contrario, aceptar \(H_0\).
4.2.3 El método de los cinco pasos (caso de no conocer \(\alpha\))
Establecer la hipótesis nula \(H_0\) y la hipótesis alternativa \(H_1\).
Seleccionar el estadístico de contraste apropiado.
Calcular el valor del estadístico de contraste a partir de los valores de la muestra.
Calcular el \(p\)-valor del contraste.
Decisión: rechazar \(H_0\) en favor de \(H_1\) si el \(p\)-valor es pequeño (\(<0.05\)), aceptar \(H_0\) si el \(p\)-valor es grande (\(\geq 0.1\)), y ampliar el estudio si el \(p\)-valor está entre 0.05 y 0.1.
Ejercicio
Los años de vida de un router sigue aproximadamente una ley de distribución normal con \(\sigma=0.89\) años.
Una muestra aleatoria de la duración de 100 aparatos ha dado una vida media de 7.18 años.
Queremos decidir si la vida media en de estos routers es superior a 7 años: \[ \left\{\begin{array}{l} H_0:\mu=7,\\ H_1:\mu>7. \end{array} \right. \]
Tomamos un nivel de significación \(\alpha=0.05\).
EL estadístico de contraste es \[ z_0=\frac{\overline{X}-7}{0.89/\sqrt{100}}=\frac{\overline{X}-7}{0.0089}=\frac{7.18-7}{0.089}=2.022. \] El \(p\)-valor es \(p=P(Z\geq 2.022)=0.022.\)
Como \(0.022<\alpha\), rechazamos \(H_0\).
Concluimos que tenemos suficientes evidencias para aceptar que la vida media de los routers es superior a los 7 años: \(\mu>7\).
Supongamos ahora que tomamos un nivel de significación \(\alpha=0.01\).
Como el \(p\)-valor \(0.022>\alpha\), no podemos rechazar \(H_0\).
En este caso, concluimos que no tenemos evidencias suficientes para rechazar que la vida media de los routers sea de 7 años o menor: \(\mu\leq 7\).
Como el p-valor obtenido, \(0.022\), es pequeño (\(<0.05\)), rechazamos \(H_0\).
Concluimos que tenemos suficientes evidencias para aceptar que la vida media de los routers es superior a los 7 años: \(\mu>7\).
4.2.4 Un último consejo
Como una regla recomendaríamos en un informe:
Si conocemos \(\alpha\), encontrar el \(p\)-valor y el intervalo de confianza del contraste para \(\alpha\) dado (nivel de confianza \((1-\alpha)\cdot 100\%\)).
Si no tenemos fijado (no conocemos) \(\alpha\), encontrar el \(p\)-valor, y el intervalo de confianza del contraste al nivel de confianza \(95\%\).
4.3 Contrastes de hipótesis para el parámetro \(\mu\) de una variable normal con \(\sigma\) desconocida
4.3.1 Contraste para \(\mu\) cuando \(n\) es grande: Z-test
Si el tamaño \(n\) de la muestra es grande (pongamos \(n\geq 40\)), podemos aplicar las reglas anteriores aunque la población no sea normal.
Si además \(\sigma\) es desconocida, ésta se puede sustituir por la desviación típica muestral \(\widetilde{S}_X\) en la expresión de \(Z\): \[ Z=\frac{\overline{X}-\mu_0} {\frac{\widetilde{S}_X}{\sqrt{n}}} \]
Ejemplo
Una organización ecologista afirma que el peso medio de los individuos adultos de una especie marina ha disminuido drásticamente.
Se sabe por los datos históricos que el peso medio poblacional era de 460 g.
Una muestra aleatoria de 40 individuos de esta especie ha dado una media muestral de 420 g. y una desviación típica muestral de 119 g.
Con estos datos, ¿podemos afirmar con un nivel de significación del 5% que el peso mediano es inferior a 460 g?
Ejemplo
El contraste que nos planteamos es el siguiente: \[\left\{\begin{array}{l} H_0:\mu=460,\\ H_1:\mu<460, \end{array} \right.\] donde \(\mu\) representa el peso medio de todos los individuos de la especie.
Consideramos un nivel de significación \(\alpha=0.05\).
Podemos usar como estadístico de contraste, como \(n=40\) es grande, la expresión: \[ Z=\frac{\overline{X}-\mu_0}{{\widetilde{S}_X}/{\sqrt{n}}}, \] cuyo valor es: \(z_0=\dfrac{420-460}{{119}/{\sqrt{40}}}=-2.126.\)
El \(p\)-valor será: \[ P(Z\leq -2.126)= 0.017. \] Decisión: como \(\alpha>p\)-valor, rechazamos (al nivel de significación \(\alpha=0.05\)) que el peso medio sea de \(460\) g. (\(H_0\)) en contra que sea menor de \(460\) g. (\(H_1\)).
Concluimos que tenemos suficientes evidencias para afirmar que el peso medio es menor que \(460\) g. y por tanto, ha menguado en los últimos años.
El intervalo de confianza será: \[ \left(-\infty, \overline{X}-z_{\alpha}\cdot \frac{\widetilde{S}_X}{\sqrt{n}}\right)=]-\infty,450.949]. \]
Informe: el \(p\)-valor de este contraste es \(0.017\), y el intervalo de confianza al nivel de significación \(\alpha=0.05\) para la media poblacional \(\mu\) es \(]-\infty,450.949]\).
Como \(460\not\in (-\infty,450.949)\), hay evidencia significativa para rechazar la hipótesis nula en favor de \(\mu<460\).
4.3.2 Contraste para \(\mu\) de normal con \(\sigma\) desconocida: T-test
Las reglas de decisión son similares al caso con \(\sigma\) conocida, excepto que ahora sustituimos \(\sigma\) por \(\widetilde{S}_X\) y empleamos la distribución \(t\) de Student.
Recordemos que si \(X_1,\ldots,X_n\) es una m.a.s. de una población normal \(X\) con mediana \(\mu_0\), la variable \(T= \frac{\overline{X}-\mu_0}{\frac{\widetilde{S}_X}{\sqrt{n}}}\) sigue una distribución t de Student con \(n-1\) grados de libertad.
Los \(p\)-valores se calculan con esta distribución.
Condiciones: supongamos que disponemos de una m.a.s. de tamaño \(n\) de una población \(N(\mu,\sigma)\) con \(\mu\) y \(\sigma\) desconocidas.
Nos planteamos los contrastes siguientes:
- \(\left\{\begin{array}{l} H_0:\mu=\mu_0 \quad (\mbox{ o } H_0:\mu\leq \mu_0)\\ H_1:\mu>\mu_0 \end{array} \right.\)
- \(\left\{\begin{array}{l} H_0:\mu=\mu_0 \quad (\mbox{ o } H_0:\mu\geq \mu_0)\\ H_1:\mu<\mu_0 \end{array} \right.\)
- \(\left\{\begin{array}{l} H_0:\mu=\mu_0 \\ H_1:\mu \neq \mu_0 \end{array} \right.\)
Para los contrastes anteriores, usaremos como estadístico de contraste: \[ T= \frac{\overline{X}-\mu_0}{\frac{\widetilde{S}_X}{\sqrt{n}}} \] y calcularemos su valor \(t_0\) sobre la muestra.
Los p-valores serán los siguientes:
- \(p\)-valor: \(P(t_{n-1}\geq t_0)\).
- \(p\)-valor: \(P(t_{n-1}\leq t_0)\).
- \(p\)-valor: \(2P(t_{n-1}\geq |t_0|)\).
Ejercicio
Se espera que el nivel de colesterol en plasma de unos enfermos bajo un determinado tratamiento se distribuya normalmente con media 220 mg/dl.
Se toma una muestra de 9 enfermos, y se miden sus niveles: \[ 203, 229, 215, 220, 223, 233, 208, 228, 209. \]
Contrastar la hipótesis que esta muestra efectivamente proviene de una población con media 220 mg/dl.
El contraste planteado es el siguiente: \[\left\{\begin{array}{l} H_0:\mu=220,\\ H_1:\mu\neq 220, \end{array} \right.\] donde \(\mu\) representa la media del colesterol en plasma de la población.
Bajo estas condiciones (población normal, \(\sigma\) desconocida, muestra pequeña de \(n=9\)) usaremos como estadístico de contraste: \(T= \frac{\overline{X}-\mu_0}{{\widetilde{S}_X}/{\sqrt9}}\) cuya distribución es \(t_8\).
El valor de dicho estadístico será:
colesterol=c(203,229,215,220,223,233,208,228,209)
media.muestral = mean(colesterol)
desv.típica.muestral = sd(colesterol)
(estadístico.contraste = (media.muestral-220)/
(desv.típica.muestral/sqrt(length(colesterol))))## [1] -0.38009147El p-valor del contraste será:
## [1] 0.7138Decisión: Como que el \(p\)-valor es muy grande, no podemos rechazar que el nivel mediano de colesterol en plasma sea igual a 220 mg/dl.
Por tanto, aceptamos que el nivel de colesterol en plasma en esta población tiene media 220 mg/dl.
El intervalo de confianza al 95% será: \[ \begin{array}{rl} \left(\overline{X}-t_{8,0.975}\frac{\widetilde{S}_X}{\sqrt{n}},\ \overline{X}+t_{8,0.975}\frac{\widetilde{S}_X}{\sqrt{n}}\right) & =\left(218.667-2.306\cdot \frac{10.524}{\sqrt{9}},218.667+2.306\cdot \frac{10.524}{\sqrt{9}}\right)\\ & =(210.577,226.756) \end{array} \]
Informe: El \(p\)-valor de este contraste es \(0.7138\) y el intervalo de confianza del \(95\%\) para el nivel medio de colesterol \(\mu\) es \((210.577,226.756)\).
Como el p-valor es grande y \(220\in (210.577,226.756)\), no hay evidencia que nos permita rechazar que \(\mu=220\).
4.3.3 Contraste de \(\mu\) de normal con \(\sigma\) desconocida en R: función t.test
La sintaxis básica de la función t.test es
donde los parámetros necesarios para realizar un contraste de una muestra son los siguientes:
xes el vector de datos que forma la muestra que analizamos.mues el valor \(\mu_0\) de la hipótesis nula: \(H_0: \mu=\mu_0\).El parámetro
alternativepuede tomar tres valores:"two.sided", para contrastes bilaterales, y"less"y"greater", para contrastes unilaterales. En esta función, y en todas las que explicamos en esta lección, su valor por defecto, que no hace falta especificar, es"two.sided". El significado de estos valores depende del tipo de test que efectuemos:"two.sided"representa la hipótesis alternativa \(H_1: \mu\neq \mu_0\),"less"corresponde a \(H_1: \mu< \mu_0\), y"greater"corresponde a \(H_1: \mu> \mu_0\).El valor del parámetro
conf.leveles el nivel de confianza \(1-\alpha\). Su valor por defecto es 0.95, que corresponde a un nivel de confianza del 95%, es decir, a un nivel de significación \(\alpha=0.05\).El parámetro
na.actionsirve para especificar qué queremos hacer con los valores NA. Es un parámetro genérico que se puede usar en casi todas las funciones de estadística inferencial y análisis de datos. Sus valores más útiles son:na.omit, su valor por defecto, elimina las entradas NA de los vectores (o los pares que contengan algún NA, en el caso de muestras emparejadas). Por ahora, esta opción por defecto es la adecuada, por lo que no hace falta usar este parámetro, pero conviene saber que hay alternativas.na.failhace que la ejecución pare si hay algún NA en los vectores.na.passno hace nada con los NA y permite que las operaciones internas de la función sigan su curso y los manejen como les corresponda.
El ejemplo anterior se resolvería de la forma siguiente:
##
## One Sample t-test
##
## data: colesterol
## t = -0.380091, df = 8, p-value = 0.71377
## alternative hypothesis: true mean is not equal to 220
## 95 percent confidence interval:
## 210.57737 226.75596
## sample estimates:
## mean of x
## 218.66667Ejercicio
Veamos si, dada una muestra de tamaño 40 de flores de la tabla de datos iris, podemos considerar que la media de la longitud del sépalo es mayor que \(5.7\).
Para ello, primero obtenemos la muestra correspondiente fijando la semilla de aleatoriedad:
Seguidamente, hallamos las longitudes del sépalo de las flores de la muestra:
## [1] 5.0 4.9 6.0 4.6 4.7 5.1 5.8 4.4 4.6 7.0 7.7 4.8 4.9 7.2 6.5 4.8 7.7 6.2 5.1
## [20] 6.8 7.2 5.0 6.7 6.9 4.6 5.7 6.4 6.1 6.4 4.7 5.0 7.7 6.2 5.0 5.1 4.9 6.3 5.0
## [39] 5.6 5.2Por último, realizamos el contraste requerido:
##
## One Sample t-test
##
## data: long.sépalo.muestra
## t = 0.236644, df = 39, p-value = 0.40709
## alternative hypothesis: true mean is greater than 5.7
## 95 percent confidence interval:
## 5.4705051 Inf
## sample estimates:
## mean of x
## 5.7375Fijémonos que se trata de un contraste de una muestra, por tanto, no ha sido necesario especificar el vector y.
El contraste que hemos realizado ha sido el siguiente: \[ \left. \begin{array}{ll} H_0: & \mu =5.7, \\ H_1: & \mu > 5.7, \end{array} \right\} \] donde \(\mu\) representa la media de la longitud del sépalo de todas las flores de la tabla de datos iris.
El p-valor obtenido ha sido 0.4071, valor superior a \(0.1\).
Por tanto, podemos concluir que no tenemos evidencias suficientes para rechazar la hipótesis nula y concluir que la media de la longitud del sépalo de las flores de la tabla de datos iris no es mayor que \(5.7\). De hecho, podemos observar en el “output” del t.test que la media de la muestra considerada vale 5.737, valor no significativamente mayor que \(5.7\).
Observamos que el t.test nos dice que el valor del estadístico de contraste es 1.499 y que dicho estadístico se distribuye según una \(t\) de Student con \(39\) grados de libertad (tamaño de la muestra, 40 menos 1).
El “output” del t.test también nos da el intervalo de confianza al 95% de confianza asociado al contraste:
## [1] 5.4705051 Inf
## attr(,"conf.level")
## [1] 0.95intervalo que contiene el valor de \(\mu_0 =5.7\), razón por la cual hemos aceptado la hipótesis nula \(H_0\).
4.3.4 Z-test contra T-test
En el caso de una población con \(\sigma\) desconocida:
Si la muestra es pequeña y la población es normal, tenemos que usar el T-test.
Si la muestra es grande y la población cualquiera, podemos usar el Z-test.
Si la muestra es grande y la población es normal, podemos usar ambos. En este último caso, os recomendamos que uséis el T-test debido a que es más preciso.
4.4 Contrastes de hipótesis para el parámetro \(p\) de una variable de Bernoulli
Supongamos que tenemos una m.a.s. de tamaño \(n\) de una población Bernoulli de parámetro \(p\).
Obtenemos \(x_0\) éxitos, de forma que la proporción muestral de éxitos será: \(\widehat{p}_X=x_0/n\)
Consideramos un contraste con hipótesis nula: \(H_0: p=p_0\)
Si \(H_0\) es verdadera, el número de éxitos sigue una distribución \(B(n,p_0)\).
Nos planteamos los contrastes siguientes:
- \(\left\{\begin{array}{l} H_0:p=p_0, \quad (\mbox{ o } H_0:p\leq p_0),\\ H_1:p>p_0. \end{array} \right.\)
- \(\left\{\begin{array}{l} H_0:p=p_0, \quad (\mbox{ o } H_0:p\geq p_0),\\ H_1:p<p_0. \end{array} \right.\)
- \(\left\{\begin{array}{l} H_0:p=p_0, \\ H_1:p\neq p_0. \end{array} \right.\)
Los p-valores serán los siguientes:
- \(p\)-valor: \(P(B(n,p_0)\geq x_0)\).
- \(p\)-valor: \(P(B(n,p_0)\leq x_0)\).
- \(p\)-valor: \(2\min\{P(B(n,p_0)\leq x_0),P(B(n,p_0)\geq x_0)\}\).
Ejemplo
Tenemos un test para detectar un determinado microorganismo. En una muestra de 25 cultivos con este microorganismo, el test lo detectó en 21 casos. Hay evidencia que la sensibilidad del test sea superior al 80%?
El contraste planteado es el siguiente:
\[\left\{\begin{array}{l} H_0:p=0.8,\\ H_1:p>0.8, \end{array} \right.\] donde \(p\) representa la probabilidad de que el test detecte el microorganismo.
Com estadístico de contraste usaremos el número de éxitos \(x_0\), que bajo la hipótesis nula \(H_0\), se distribuye según una \(B(25,0.8)\).
El valor del estadístico de contraste es: \(x_0=21\)
El \(p\)-valor será: \[ P(B(25,0.8)\geq 21) =\mathtt{1-pbinom(20,25,0.8)}= 0.421. \]
Decisión: como el \(p\)-valor es muy grande, no podemos rechazar la hipótesis nula.
No hay evidencia que la sensibilidad de la test sea superior al 80%.
4.4.1 Contrastes para proporciones en R
Este test está implementado en la función binom.test, cuya sintaxis es
donde
xynson números naturales: el número de éxitos y el tamaño de la muestra.pes la probabilidad de éxito que queremos contrastar.
Puede ser útil saber que el intervalo de confianza para la \(p\) que da binom.test en un contraste bilateral es el de Clopper-Pearson.
El contraste anterior sería en R:
##
## Exact binomial test
##
## data: 21 and 25
## number of successes = 21, number of trials = 25, p-value = 0.42067
## alternative hypothesis: true probability of success is greater than 0.8
## 95 percent confidence interval:
## 0.6703917 1.0000000
## sample estimates:
## probability of success
## 0.84Ejercicio
Consideremos la tabla de datos birthwt del paquete MASS. Dicha tabla de datos contiene información acerca de 189 recién nacidos en un hospital de Springfield en el año 1986.
Las variables consideradas son las siguientes:
- low: indicador de si el peso del recién nacido ha sido menor que 2.5 kg.
- age: edad de la madre en años.
- lwt: peso de la madre en libras durante el último período.
- race: raza de la madre (1: blanca, 2: negra, 3: otra)
- smoke: indicador de si la madre fumaba durante el embarazo.
- ptl: número de embarazos previos de la madre.
- ht: indicador de si la madre es hipertensa.
- ui: indicador de irritabilidad uterina en la madre.
- ftw: número de visitas médicas realizadas durante el primer trimestre.
- bwt: peso del recién nacido en gramos.
Vamos a contrastar si la proporción de madres fumadoras supera el 30%: \[ \left. \begin{array}{ll} H_0: & p = 0.3, \\ H_1: & p> 0.3, \end{array} \right\} \]
donde \(p\) representa la proporción de madres fumadoras.
En primer lugar consideramos una muestra de tamaño 30:
library(MASS)
set.seed(1001)
madres.elegidas=sample(1:189,30,replace=TRUE)
muestra.madres.elegidas=birthwt[madres.elegidas,]A continuación vemos cuál es el número de “éxitos” o número de madres fumadoras:
##
## 0 1
## 14 16Tenemos un total de 16 madres fumadoras en nuestra muestra de 30 madres.
Por último realizamos el contraste planteado:
número.madres.fumadoras=table(muestra.madres.elegidas$smoke)[2]
binom.test(número.madres.fumadoras,30,p=0.3,alternative="greater")##
## Exact binomial test
##
## data: número.madres.fumadoras and 30
## number of successes = 16, number of trials = 30, p-value = 0.0063703
## alternative hypothesis: true probability of success is greater than 0.3
## 95 percent confidence interval:
## 0.36994756 1.00000000
## sample estimates:
## probability of success
## 0.53333333Como el p-valor del contraste es prácticamente nulo, concluimos que tenemos evidencias suficientes para afirmar que la proporción de madres fumadoras supera el 30%.
Si nos fijamos en el intervalo de confianza para la proporción asociado al contraste:
## [1] 0.36994756 1.00000000
## attr(,"conf.level")
## [1] 0.95vemos que no contiene la proporción 0.3, hecho que nos reafirma la conclusión anterior.
4.4.2 Contrastes para proporciones cuando \(n\) es grande
Si indicamos con \(p\) la proporción poblacional y \(\widehat{p}_X\) la proporción muestral, sabemos que si la muestra es grande \((n\geq 40)\) \(Z=\frac{\widehat{p}_X-p}{\sqrt{\frac{p(1-p)}{n}}}\approx N(0,1).\)
Si la hipótesis nula \(H_0:p=p_0\) es verdadera, \(Z=\frac{\widehat{p}_X-p_0}{\sqrt{\frac{p_0(1-p_0)}{n}}}\approx N(0,1).\)
Podemos usar los mismos \(p\)-valores que en el \(Z\)-test.
Se tiene que ir alerta con el intervalo de confianza. Si tenemos \(n\geq 100\), \(n\hat{p}_X\geq 10\) y \(n(1-\hat{p}_X)\geq 10\), se puede usar el de Laplace. En caso contrario, se tiene que usar el de Wilson.
Ejercicio
Una asociación ganadera afirma que, en las matanzas caseras en las Baleares, como mínimo el 70% de los cerdos han sido analizados de triquinosis.
En una investigación, se visita una muestra aleatoria de 100 matanzas y resulta que en 53 de éstas se ha realizado el análisis de triquinosis.
¿Podemos aceptar la afirmación de los ganaderos?
El contraste planteado es el siguiente: \[\left\{\begin{array}{l} H_0:p\geq 0.7,\\ H_1:p<0.7, \end{array} \right.\] donde \(p\) representa la probabilidad de que en una matanza elegida al azar, ésta sea analizada de triquinosis.
El estadístico de contraste será: \[ Z=\frac{\widehat{p}_X-p_0}{\sqrt{\frac{p_0(1-p_0)}{n}}}, \] cuyo valor es: \[ \widehat{p}_X=\frac{53}{100}=0.53\Longrightarrow z_0=\frac{0.53-0.7}{\sqrt{\frac{0.7\cdot 0.3}{100}}}=-3.71. \]
El \(p\)-valor del contraste será: \[ P(Z\leq -3.71)=0. \]
Decisión: como el \(p\)-valor es muy pequeño, rechazamos la hipótesis nula en favor de la alternativa.
¡Podemos afirmar con contundencia que la afirmación de los ganaderos es falsa!
El intervalo de confianza al 95% de confianza será en este caso: \[ \left(-\infty,\widehat{p}_X-z_{0.05}\sqrt{\frac{\widehat{p}_X(1-\widehat{p}_X)}{n}}\right)=\left(-\infty,0.53 -(-1.645)\cdot \sqrt{\frac{0.53\cdot 0.47}{100}}\right) = \left(-\infty,0.612\right). \]
Informe: El \(p\)-valor de este contraste es prácticamente nulo y el intervalo de confianza del \(95\%\) para la proporción \(p\) de matanzas donde se han hecho análisis de triquinosi es \(\left(-\infty,0.612\right)\).
Como el \(p\)-valor es muy pequeño y \(0.7\not\in \left(-\infty,0.612\right)\), hay evidencia muy significativa para rechazar que \(p=0.7\).
En R está implementado en la función prop.test, que además también sirve para contrastar dos proporciones por medio de muestras independientes grandes. Su sintaxis es
donde:
xpuede ser dos cosas:- Un número natural: en este caso,
Rentiende que es el número de éxitos en una muestra. - Un vector de dos números naturales: en este caso,
Rentiende que es un contraste de dos proporciones y que éstos son los números de éxitos en las muestras.
- Un número natural: en este caso,
Cuando trabajamos con una sola muestra,
nes su tamaño. Cuando estamos trabajando con dos muestras,nes el vector de dos entradas de sus tamaños.Cuando trabajamos con una sola muestra,
pes la proporción poblacional que contrastamos. En el caso de un contraste de dos muestras, no hay que especificarlo.El significado de
alternativeyconf.level, y sus posibles valores, son los usuales.
La resolución del ejemplo anterior con R es la siguiente:
##
## 1-sample proportions test with continuity correction
##
## data: 53 out of 100, null probability 0.7
## X-squared = 12.9643, df = 1, p-value = 0.00015874
## alternative hypothesis: true p is less than 0.7
## 95 percent confidence interval:
## 0.00000000 0.61503639
## sample estimates:
## p
## 0.53R usa como estadístico de contraste \(Z^2\) donde \(Z\) recordemos que es:
\(Z=\frac{\widehat{p}_X-p_0}{\sqrt{\frac{p_0(1-p_0)}{n}}}\).
Si hacemos \(z_0^2\) obtenemos:
## [1] 13.761905No da exactamente el mismo valor en la salida de R de la función prop.test debido a que R hace una pequeña corrección a la continuidad.
Este hecho también se manifiesta en la pequeña diferencia que hay en los intervalos de confianza calculados a mano y en la salida de R.
4.5 Contrastes de hipótesis para el parámetro \(\sigma\) de una variable con distribución normal
Recordamos que si \(X_1,\ldots,X_n\) es una m.a.s. de una v.a. \(X\sim N(\mu,\sigma)\), entonces el estadístico \(\chi_{n-1}^2=\frac{(n-1)\widetilde{S}_X^2}{\sigma^2}\) sigue una distribución \(\chi^2\) con \(n-1\) grados de libertad
Por lo tanto, si la hipótesis nula \(H_0:\sigma=\sigma_0\) es verdadera, \(\chi_{n-1}^2=\frac{(n-1) \widetilde{S}_X^2}{\sigma_0^2}\) tendrá una distribución \(\chi^2\) con \(n-1\) grados de libertad.
Calculamos su valor \(\chi^2_0\) sobre la muestra.
Nos planteamos los contrastes siguientes:
- \(\left\{\begin{array}{l} H_0:\sigma=\sigma_0, \quad (\mbox{ o } H_0:\sigma\leq \sigma_0),\\ H_1:\sigma>\sigma_0. \end{array} \right.\)
- \(\left\{\begin{array}{l} H_0:\sigma=\sigma_0, \quad (\mbox{ o } H_0:\sigma\geq \sigma_0),\\ H_1:\sigma<\sigma_0. \end{array} \right.\)
- \(\left\{\begin{array}{l} H_0:\sigma=\sigma_0, \\ H_1:\sigma\neq \sigma_0. \end{array} \right.\)
Los p-valores serán los siguientes:
- \(p\)-valor: \(P(\chi^2_{n-1}\geq \chi^2_0)\).
- \(p\)-valor: \(P(\chi^2_{n-1}\leq \chi^2_0)\).
- \(p\)-valor: \(2\min\big\{P(\chi_{n-1}^2\leq \chi^2_0), P(\chi_{n-1}^2\geq \chi^2_0)\big\}\).
Ejercicio
Se han medido los siguientes valores en miles de personas para la audiencia de un programa de radio en \(n=10\) días: \[ 521, 742, 593, 635, 788, 717, 606, 639, 666, 624 \]
Contrastar si la varianza de la audiencia es 6400 al nivel de significación del 5%, suponiendo que la población es normal.
El contraste de hipótesis planteado es el siguiente: \[\left\{\begin{array}{l} H_0:\sigma=\sqrt{6400}=80, \\ H_1:\sigma\neq 80. \end{array} \right.\]
El nivel de significación serà: \(\alpha=0.05\)
El estadístico de contraste es: \[ \chi_{n-1}^2=\frac{(n-1) \widetilde{S}_X^2}{\sigma_0^2}. \]
Su valor será:
## [1] 8.5945156El \(p\)-valor será: \[ \begin{array}{rl} 2\cdot P(\chi_9^2\geq 8.595) & =0.951,\\ 2\cdot P(\chi_9^2\leq 8.595) &=1.049. \end{array} \]
Tomamos como \(p\)-valor el más pequeño: \(0.951\)
Decisión: No podemos rechazar la hipótesis que la varianza sea 6400 al nivel de significación del 5%.
El intervalo de confianza del 95% de confianza será: \[ \left( \frac{(n-1)\widetilde{S}_{X}^2}{\chi_{n-1,0.975}^2}, \frac{(n-1)\widetilde{S}_{X}^2}{\chi_{n-1,0.025}^2} \right)=(2891.53,20369.247) \]
Informe: El \(p\)-valor de este contraste es \(0.951\), y el intervalo de confianza del \(95\%\) para la varianza \(\sigma^2\) de la audiencia es \((2891.53,20369.247)\).
Como el \(p\)-valor es muy grande y \(6400\in (2891.53,20369.247)\), no hay evidencia que nos permita rechazar que \(\sigma^2=6400\).
Dicho test está convenientemente implementado en la función sigma.test del paquete TeachingDemos.
Su sintaxis es la misma que la de la función t.test para una muestra, substituyendo el parámetro mu de t.test por el parámetro sigma (para especificar el valor de la desviación típica que contrastamos, \(\sigma_0\)) o sigmasq (por “sigma al cuadrado”, para especificar el valor de la varianza que contrastamos, \(\sigma_0^2\)).
El ejemplo anterior se resolvería de la forma siguiente:
##
## One sample Chi-squared test for variance
##
## data: x
## X-squared = 8.6, df = 9, p-value = 1
## alternative hypothesis: true variance is not equal to 6400
## 95 percent confidence interval:
## 2892 20369
## sample estimates:
## var of x
## 6112Ejemplo
Vamos a contrastar si la varianza de la amplitud del sépalo de las flores de la tabla de datos iris es menor que \(0.2\).
En primer lugar consideremos una muestra de 40 flores:
set.seed(2019)
flores.elegidas=sample(1:150,40,replace=TRUE)
muestra.flores.elegidas = iris[flores.elegidas,]A continuación realizamos el contraste: \[ \left. \begin{array}{ll} H_0: & \sigma^2 = 0.2, \\ H_1: & \sigma^2 < 0.2, \end{array} \right\} \] donde \(\sigma^2\) representa la varianza de la amplitud del sépalo de las flores de la tabla de datos iris.
El contraste anterior, en R, se realiza de la forma siguiente:
library(TeachingDemos)
sigma.test(muestra.flores.elegidas$Sepal.Width,sigmasq = 0.2,alternative = "less")##
## One sample Chi-squared test for variance
##
## data: muestra.flores.elegidas$Sepal.Width
## X-squared = 45, df = 39, p-value = 0.8
## alternative hypothesis: true variance is less than 0.2
## 95 percent confidence interval:
## 0.0000 0.3531
## sample estimates:
## var of muestra.flores.elegidas$Sepal.Width
## 0.2327El p-valor del contraste ha sido 0.7763, valor muy superior a 0.1.
Concluimos por tanto, que no tenemos evidencias suficientes para aceptar que la varianza de la amplitud del sépalo sea menor que 0.2.
Si observamos el intervalo de confianza,
## [1] 0.0000 0.3531
## attr(,"conf.level")
## [1] 0.95vemos que el valor 0.2 está en él, hecho que nos reafirma nuestra conclusión.
4.6 Contrastes de hipótesis para dos muestras
Queremos comparar el valor de un mismo parámetro en dos poblaciones.
Para ello dispondremos de una muestra para cada población.
Hay que tener en cuenta que las muestras pueden ser de dos tipos:
- Muestras independientes: las dos muestras se han obtenido de manera independiente.
Ejemplo
Probamos un medicamento sobre dos muestras de enfermos de características diferentes
- Muestras emparejadas: las dos muestras corresponden a los mismos individuos, o a individuos aparejados de alguna manera.
Ejemplo
Probamos dos medicamentos sobre los mismos enfermos.
4.6.1 Muestras independientes
Tenemos dos variables aleatorias (que representan los valores de la característica a estudiar sobre dos poblaciones).
Ejemplo
Poblaciones: Hombres y Mujeres. Característica a estudiar: estatura.
Queremos comparar el valor de un parámetro a las dos poblaciones
Ejemplo
¿Son, de media, los hombres más altos que las mujeres?
Lo haremos a partir de una m.a.s. de cada v.a., escogidas además de manera independiente.
4.7 Contrastes para dos medias poblacionales independientes \(\mu_1\) y \(\mu_2\)
Tenemos dos v.a. \(X_1\) y \(X_2\), de medias \(\mu_1\) y \(\mu_2\)
Tomamos una m.a.s. de cada variable: \[ \begin{array}{l} X_{1,1}, X_{1,2},\ldots, X_{1,n_1},\mbox{ de }X_1\\ X_{2,1}, X_{2,2},\ldots, X_{2,n_2},\mbox{ de }X_2 \end{array} \] Sean \(\overline{X}_1\) y \(\overline{X}_2\) sus medias, respectivamente.
La hipótesis nula será del tipo: \[ H_0: \mu_1 = \mu_2,\mbox{ o, equivalentemente, }H_0:\mu_1-\mu_2 = 0.\\ \]
Las hipótesis alternativas que nos plantearemos serán del tipo: \[ \begin{array}{l} \mu_1 < \mu_2,\mbox{ o, equivalentemente, }\mu_1-\mu_2<0,\\ \mu_1 > \mu_2,\mbox{ o, equivalentemente, }\mu_1-\mu_2>0,\\ \mu_1 \neq \mu_2,\mbox{ o, equivalentemente, }\mu_1-\mu_2\neq 0. \end{array} \]
4.7.1 Poblaciones normales o \(n\) grandes: \(\sigma\) conocidas
Suponemos una de las dos situaciones siguientes:
- \(X_1\) y \(X_2\) son normales, o \(n_1\) y \(n_2\) son grandes (\(n_1,n_2\geq 30\mbox{ o } 40)\)
Suponemos que conocemos además las desviaciones típicas \(\sigma_1\) y \(\sigma_2\) de \(X_1\) y \(X_2\), respectivamente.
En este caso el estadístico de contraste es \(Z=\frac{\overline{X}_1-\overline{X}_2}{\sqrt{\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}}},\) que, si la hipótesis nula es cierta (\(\mu_1=\mu_2\)), se distribuye según una \(N(0,1)\).
Sea \(z_0\) el valor del estadístico de contraste sobre la muestra. Los \(p\)-valores dependiendo de la hipótesis alternativa son:
- \(H_1:\mu_1 >\mu_2\): \(p=P(Z \geq z_0)\).
- \(H_1:\mu_1 <\mu_2\): \(p=P(Z \leq z_0)\).
- \(H_1:\mu_1 \neq \mu_2\): \(p=2\cdot P(Z \geq |z_0|)\).
Ejemplo
Queremos comparar los tiempos de realización de una tarea entre estudiantes de dos grados \(G_1\) y \(G_2\), y contrastar si es verdad que los estudiantes de \(G_1\) emplean menos tiempo que los de \(G_2\)
Suponemos que las desviaciones típicas son conocidas: \(\sigma_1=1\) y \(\sigma_2=2\)
Disponemos de dos muestras independientes de tiempos realizados por estudiantes de cada grado, de tamaños \(n_1=n_2=40\). Calculamos las medias de los tiempos empleados en cada muestra (en minutos): \[ \overline{X}_1= 9.789,\quad \overline{X}_2=11.385 \]
El contraste planteado es el siguiente: \[ \left\{\begin{array}{l} H_0:\mu_1=\mu_2\\ H_1:\mu_1< \mu_2 \end{array}\right. \Longleftrightarrow \left\{\begin{array}{l} H_0:\mu_1-\mu_2=0\\ H_1:\mu_1- \mu_2<0 \end{array}\right. \]
El estadístico de contraste toma el valor: \(z_0=\dfrac{\overline{X}_1-\overline{X}_2}{\sqrt{\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}}}=\frac{9.789-11.385}{\sqrt{\frac{1^2}{40}+\frac{2^2}{40}}}=-4.514\).
El \(p\)-valor será: \(P(Z\leq -4.514)\approx 0\) muy pequeño.
Decisión: rechazamos la hipótesis de que son iguales, en favor de que los alumnos del grado \(G_1\) tardan menos que los del grado \(G_2\).
Si calculamos un intervalo de confianza del 95% para la diferencia de medias \(\mu_1-\mu_2\) asociado al contraste anterior, obtenemos: \[ \begin{array}{ll} \left( -\infty, \overline{X}_1 -\overline{X}_2 -z_{0.05}\sqrt{\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}}\right) & = \left(-\infty,9.789-11.385 +1.645\cdot \sqrt{\frac{1^2}{40}+\frac{2^2}{40}}\right) \\ & = (-\infty, -1.014). \end{array} \] Observamos que el valor \(0\) no pertenece al intervalo de confianza anterior, hecho que nos hace reafirmar la decisión de rechazar \(H_0:\mu_1-\mu_2=0\).
4.7.2 Poblaciones normales o \(n\) grandes: \(\sigma_1\) o \(\sigma_2\) desconocidas
Suponemos otra vez que estamos en una de las dos situaciones siguientes, pero ahora no conocemos \(\sigma_1\) o \(\sigma_2\):
\(X_1\) y \(X_2\) son normales, o
\(n_1\) y \(n_2\) son grandes (\(n_1,n_2\geq 40)\).
Recordemos que disponemos de una m.a.s. de cada variable: \[ \begin{array}{l} X_{1,1}, X_{1,2},\ldots, X_{1,n_1},\mbox{ de }X_1,\\ X_{2,1}, X_{2,2},\ldots, X_{2,n_2},\mbox{ de }X_2. \end{array} \]
En este caso, tenemos que distinguir dos subcasos:
- Suponemos que \(\sigma_1=\sigma_2\).
- Suponemos que \(\sigma_1\neq \sigma_2\).
¿Como decidimos en qué caso estamos? Dos posibilidades:
- Realizamos los dos casos, y si dan lo mismo, es lo que contestamos.
- En caso de poblaciones normales, realizamos un contraste de igualdad de varianzas para decidir cuál es el caso.
Si suponemos que \(\sigma_1=\sigma_2\), el estadístico de contraste es \[ T=\frac{\overline{X}_1-\overline{X}_2} {\sqrt{(\frac1{n_1}+\frac1{n_2})\cdot \frac{((n_1-1)\widetilde{S}_1^2+(n_2-1)\widetilde{S}_2^2)} {(n_1+n_2-2)}}}, \] que, cuando \(\mu_1=\mu_2\), tiene distribución (aproximadamente, en caso de muestras grandes) \(t_{n_1+n_2-2}\).
Si suponemos que \(\sigma_1\neq \sigma_2\), el estadístico de contraste es \(T=\frac{\overline{X}_1-\overline{X}_2}{\sqrt{\frac{\widetilde{S}_1^2}{n_1}+\frac{\widetilde{S}_2^2}{n_2}}}\sim t_f,\) que, cuando \(\mu_1=\mu_2\), tiene distribución (aproximadamente, en caso de muestras grandes) \(t_{f}\) con \[ f=\left\lfloor\frac{\displaystyle \left( \frac{\widetilde{S}_1^2}{n_1}+\frac{\widetilde{S}_2^2}{n_2}\right)^2} {\displaystyle \frac1{n_1-1}\left(\frac{\widetilde{S}_1^2}{n_1}\right)^2+\frac1{n_2-1}\left(\frac{\widetilde{S}_2^2}{n_2}\right)^2}\right\rfloor -2. \]
Los \(p\)-valores usando las mismas expresiones que en el caso en que \(\sigma_1\) y \(\sigma_2\) conocidas sustituyendo el estadístico de contraste \(Z\) por el estadístico de contraste correspondiente.
Ejemplo
Queremos comparar los tiempos de realización de una tarea entre estudiantes de dos grados \(G_1\) y \(G_2\), y determinar si es verdad que los estudiantes de \(G_1\) emplean menos tiempo que los de \(G_2\) suponiendo que desconocemos una o las dos desviaciones típicas poblaciones \(\sigma_1\) y \(\sigma_2\).
Disponemos de dos muestras independientes de tiempos de tareas realizadas por estudiantes de cada grado de tamaños \(n_1=40\) y \(n_2=60\). Las medias y las desviaciones típicas muestrales de los tiempos empleados para cada muestra son: \[ \overline{X}_1= 9.789,\ \overline{X}_2=11.385,\ \widetilde{S}_1=1.201,\ \widetilde{S}_2=1.579. \]
El contraste a realizar es el siguiente: \[ \left\{\begin{array}{l} H_0:\mu_1=\mu_2,\\ H_1:\mu_1< \mu_2, \end{array}\right. \Longleftrightarrow \left\{\begin{array}{l} H_0:\mu_1-\mu_2=0,\\ H_1:\mu_1- \mu_2<0, \end{array}\right. \] donde \(\mu_1\) y \(\mu_2\) representan los tiempos medios que tardan los estudiantes de los grados \(G_1\) y \(G_2\) para realizar la tarea, respectivamente.
Consideremos los dos casos anteriores:
- Caso 1: Suponemos \(\sigma_1=\sigma_2\).
El estadístico de contraste es: \(T=\frac{\overline{X}_1-\overline{X}_2} {\sqrt{(\frac1{n_1}+\frac1{n_2})\cdot \frac{((n_1-1)\widetilde{S}_1^2+(n_2-1)\widetilde{S}_2^2)} {(n_1+n_2-2)}}}\sim t_{40+60-2}=t_{98},\) cuyo valor, usando los valores correspondientes de las muestras, será: \(t_0=\frac{9.789-11.385}{\sqrt{(\frac1{40}+\frac1{60})\frac{(39\cdot 1.201^2+59\cdot 1.579^2)}{98}}}=-5.428.\)
El \(p\)-valor será, en este caso: \(P(t_{78}<-5.428)\approx 0,\) valor muy pequeño.
La decisión que tomamos, por tanto, es rechazar la hipótesis de que son iguales, en favor de que los estudiantes del grado \(G_1\) tardan menos tiempo en realizar la tarea que los estudiantes del grado \(G_2\).
Consideremos ahora el otro caso:
- Caso 2: Suponemos \(\sigma_1\neq \sigma_2\).
El estadístico de contraste será, en este caso: \(T=\frac{\overline{X}_1-\overline{X}_2}{\sqrt{\frac{\widetilde{S}_1^2}{n_1}+\frac{\widetilde{S}_2^2}{n_2}}}\sim t_f\) donde \[ f=\left\lfloor\frac{ \left( \frac{1.201^2}{40}+\frac{1.201^2}{60}\right)^2} {\frac1{39}\left(\frac{1.201^2}{40}\right)^2+\frac1{59}\left(\frac{1.579^2}{60}\right)^2}\right\rfloor -2 =\lfloor 96.22\rfloor-2=94. \]
El valor que toma el estadístico anterior será: \[ t_0=\frac{9.789-11.385}{\sqrt{\frac{1.201^2}{40}+\frac{1.579^2}{60}}}=-5.729. \]
El \(p\)-valor del contraste será: \(P(t_{94}\leq -5.729)= 0,\) valor muy pequeño.
La decisión que tomamos en este caso es la misma que en el caso anterior: rechazar la hipótesis de que los tiempos de ejecución son iguales, en favor de que los alumnos del grado \(G_1\) tardan menos tiempo en realizar la tarea que los alumnos del grado \(G_2\).
La decisión final, al haber decidido lo mismo en los dos casos, será concluir que los alumnos del grado \(G_1\) tardan menos tiempo en realizar la tarea que los alumnos del grado \(G_2\).
4.7.3 Contrastes para dos medias independientes en R: función t.test
Recordemos la sintaxis básica de la función t.test es
donde los nuevos parámetros para realizar un contraste de dos medias independientes son:
xes el vector de datos de la primera muestra.yes el vector de datos de la segunda muestra.Podemos sustituir los vectores
xeypor una fórmulavariable1~variable2que indique que separamos la variable numéricavariable1en dos vectores definidos por los niveles de un factorvariable2de dos niveles (o de otra variable asimilable a un factor de dos niveles, como por ejemplo una variable numérica que solo tome dos valores diferentes).Parámetro
alternative:- Si llamamos \(\mu_x\) y \(\mu_y\) a las medias de las poblaciones de las que hemos extraído las muestras \(x\) e \(y\), respectivamente, entonces
"two.sided"representa la hipótesis alternativa \(H_1: \mu_x \neq \mu_y\);"less"indica que la hipótesis alternativa es \(H_1: \mu_x< \mu_y\); y"greater", que la hipótesis alternativa es \(H_1: \mu_x> \mu_y\).
- Si llamamos \(\mu_x\) y \(\mu_y\) a las medias de las poblaciones de las que hemos extraído las muestras \(x\) e \(y\), respectivamente, entonces
El parámetro
var.equalsolo lo tenemos que especificar si llevamos a cabo un contraste de dos medias usando muestras independientes, y en este caso sirve para indicar si queremos considerar las dos varianzas poblacionales iguales (igualándolo a TRUE) o diferentes (igualándolo a FALSE, que es su valor por defecto).
Ejercicio
Imaginemos ahora que nos planteamos si la media de la longitud del pétalo es la misma para las flores de las especies setosa y versicolor.
Para ello seleccionamos una muestra de tamaño 40 flores para cada especie:
set.seed(45)
flores.elegidas.setosa = sample(1:50,40,replace=TRUE)
flores.elegidas.versicolor = sample(51:100,40,replace=TRUE)Las muestras serán las siguientes:
muestra.setosa = iris[flores.elegidas.setosa,]
muestra.versicolor = iris[flores.elegidas.versicolor,]El contraste planteado se realiza de la forma siguiente:
##
## Welch Two Sample t-test
##
## data: muestra.setosa$Petal.Length and muestra.versicolor$Petal.Length
## t = -43, df = 50, p-value <0.0000000000000002
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -2.913 -2.652
## sample estimates:
## mean of x mean of y
## 1.407 4.190El contraste realizado es de dos muestras independientes: \[ \left. \begin{array}{ll} H_0: & \mu_{{setosa}} =\mu_{{versicolor}}, \\ H_1: & \mu_{{setosa}} \neq \mu_{{versicolor}}, \end{array} \right\} \] donde \(\mu_{{setosa}}\) representa la media de la longitud del pétalo de las flores de la especie setosa y \(\mu_{{versicolor}}\), la media de la longitud del pétalo de las flores de la especie versicolor.
El p-valor del contraste ha sido pràcticamente cero, lo que nos hace concluir que tenemos evidencias suficientes para concluir que las medias de la longitud del pétalo son diferentes para las dos especies.
De hecho, las medias de cada una de la dos muestras son 1.4075 y 4.19, valores muy diferentes.
El intervalo de confianza al 95% de confianza para la diferencia de medias \(\mu_{{setosa}}-\mu_{{versicolor}}\) asociado al contraste anterior vale, si nos fijamos en el “output” del t.test:
t.test(muestra.setosa$Petal.Length,muestra.versicolor$Petal.Length,
alternative="two.sided")$conf.int## [1] -2.913 -2.652
## attr(,"conf.level")
## [1] 0.95intervalo que no contiene el valor cero y está totalmente a la izquierda de cero. Por tanto, debemos rechazar la hipótesis nula.
Fijémonos que hemos considerado que las varianzas de las dos variables son diferentes. Si las hubiésemos considerado iguales, tendríamos que hacer:
t.test(muestra.setosa$Petal.Length,muestra.versicolor$Petal.Length,
alternative="two.sided",var.equal = TRUE)##
## Two Sample t-test
##
## data: muestra.setosa$Petal.Length and muestra.versicolor$Petal.Length
## t = -43, df = 78, p-value <0.0000000000000002
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -2.912 -2.653
## sample estimates:
## mean of x mean of y
## 1.407 4.190En este caso, el p-valor también es despreciable, por lo que llegamos a la misma conclusión anterior: las medias son diferentes.
Más adelante veremos cómo realizar un contraste de varianzas para comprobar si éstas son iguales o no y por tanto, actuar en consecuencia con el parámetro var.equal.
4.8 Contrastes para dos proporciones \(p_1\) y \(p_2\)
4.8.1 Test de Fisher
Tenemos dos variables aleatorias \(X_1\) y \(X_2\) Bernoulli de proporciones \(p_1\) y \(p_2\)
Tomamos m.a.s. de cada una y obtenemos la tabla siguiente:
| \(X_1\) | \(X_2\) | Total | |
|---|---|---|---|
| Éxitos | \(n_{11}\) | \(n_{12}\) | \(n_{1\bullet}\) |
| Fracasos | \(n_{21}\) | \(n_{22}\) | \(n_{2\bullet}\) |
| Total | \(n_{\bullet 1}\) | \(n_{\bullet 2}\) | \(n_{\bullet\bullet}\) |
donde \(n_{11}\) es la cantidad de éxitos en la primera muestra, \(n_{12}\), la cantidad de éxitos en la segunda muestra, \(n_{21}\), la cantidad de fracasos en la primera muestra y \(n_{22}\), la cantidad de fracasos en la segunda muestra.
De la misma forma, \(n_{1\bullet}\), es la cantidad total de éxitos en las dos muestras y \(n_{2\bullet}\) la cantidad total de fracasos en las dos muestras.
Por último, \(n_{\bullet 1}\) es el tamaño de la primera muestra, \(n_{\bullet 2}\), el tamaño de la segunda muestra y \(n_{\bullet\bullet}=n_{\bullet 1}+n_{\bullet 2}\) es la suma de los dos tamaños.
Supongamos \(p_1=p_2\).
Para hallar la probabilidad de obtener \(n_{11}\) éxitos para la variable \(X_1\) podemos razonar de la forma siguiente:
En una bolsa tenemos \(n_{1\bullet}\) bolas E y \(n_{2\bullet}\) bolas F. La probabilidad anterior sería la probabilidad de obtener \(n_{11}\) bolas E si escogemos \(n_{\bullet 1}\) de golpe.
Sea \(X\) una variable hipergeométrica de parámetros \(H(n_{1\bullet},n_{2\bullet},n_{\bullet1})\). La probabilidad anterior sería: \(P(X=n_{11})\).
Usaremos la variable anterior \(X\) como estadístico de contraste.
Nos planteamos los contrastes siguientes:
- \(\left\{\begin{array}{l} H_0:p_1=p_2,\\ H_1:p_1> p_2. \end{array}\right.\)
- \(\left\{\begin{array}{l} H_0:p_1=p_2,\\ H_1:p_1< p_2. \end{array}\right.\)
- \(\left\{\begin{array}{l} H_0:p_1=p_2,\\ H_1:p_1\neq p_2. \end{array}\right.\)
Los p-valores serán los siguientes:
- \(p\)-valor: \(P(H(n_{1\bullet},n_{2\bullet},n_{\bullet1})\geq n_{11})\).
- \(p\)-valor: \(P(H(n_{1\bullet},n_{2\bullet},n_{\bullet1})\leq n_{11})\).
- \(p\)-valor: \(2\min\{P(H\leq n_{11}), P(H\geq n_{11})\}\).
Ejemplo
Para determinar si el Síndrome de Muerte Repentina del Bebé (SIDS) tiene componiendo genético, se consideran los casos de SIDS en parejas de gemelos monocigóticos y dicigóticos. Sea:
\(p_1\): proporción de parejas de gemelos monocigóticos con algún caso de SIDS donde solo un hermano la sufrió.
\(p_2\): proporción de parejas de gemelos dicigóticos con algún caso de SIDS donde solo un hermano la sufrió.
Si el SIDS tiene componiendo genético, es de esperar que \(p_1<p_2\).
Nos piden realizar el contraste siguiente: \[ \left\{\begin{array}{l} H_0:p_1=p_2,\\ H_1:p_1< p_2. \end{array}\right. \]
En un estudio (Peterson et al, 1980), se obtuvieron los datos siguientes:
| Casos de SIDS | Monocigóticos | Dicigóticos | Total |
|---|---|---|---|
| Uno | 23 | 35 | 58 |
| Dos | 1 | 2 | 3 |
| Total | 24 | 37 | 61 |
El p-valor del contraste anterior sería: \(P(H(58,3,24)\leq 23)\):
## [1] 0.7841Al obtener un \(p\)-valor grande, podemos concluir que no tenemos evidencias suficientes para rechazar la hipótesis nula y por tanto, el SID no tiene componente genética.
- El test exacto de Fisher está implementado en la función
fisher.test. Su sintaxis es
donde
xes la matriz anterior, donde recordemos que los números de éxitos van en la primera fila y los de fracasos en la segunda, y las poblaciones se ordenan por columnas.
Ejercicio
Realicemos el contraste anterior de igualdad de proporciones de madres fumadores de raza blanca y negra usando el test de Fisher.
En primer lugar calculamos las etiquetas de las madres de cada raza:
madres.raza.blanca = rownames(birthwt[birthwt$race==1,])
madres.raza.negra = rownames(birthwt[birthwt$race==2,])Seguidamente, elegimos las muestras de tamaño 50 de cada raza y creamos las muestras correspondientes:
set.seed(2000)
madres.elegidas.blanca=sample(madres.raza.blanca,50,replace=TRUE)
madres.elegidas.negra = sample(madres.raza.negra,50, replace=TRUE)
muestra.madres.raza.blanca = birthwt[madres.elegidas.blanca,]
muestra.madres.raza.negra = birthwt[madres.elegidas.negra,]Definimos ahora una nueva tabla de datos que contenga la información de las dos muestras consideradas:
A continuación calculamos la matriz para usar en el test de Fisher:
##
## 1 2
## 0 24 33
## 1 26 17La matriz anterior no es correcta ya que la primera fila debería ser la fila de “éxitos” y es la fila de “fracasos”.
Lo arreglamos permutando las filas:
## 1 2
## [1,] 26 17
## [2,] 24 33Por último realizamos el contraste:
##
## Fisher's Exact Test for Count Data
##
## data: matriz.fisher
## p-value = 0.1
## alternative hypothesis: true odds ratio is not equal to 1
## 95 percent confidence interval:
## 0.8723 5.1038
## sample estimates:
## odds ratio
## 2.087El p-valor del contraste ha sido 0.1056, valor mayor que 0.1. Concluimos que no tenemos evidencias para rechazar que las proporciones de madres fumadoras de razas blanca y negra sean iguales.
O, dicho de otra manera, no rechazamos la hipótesis nula de igualdad de proporciones.
Ejercicio
Como el test de Fisher es exacto, dejamos como ejercicio repetir el experimento anterior pero en lugar de tomando muestras de tamaño 50, tomando muestras de tamaño más pequeño como por ejemplo 10.
Hay que ir con cuidado con la interpretación del intervalo de confianza que da esta función: no es ni para la diferencia de las proporciones ni para su cociente, sino para su odds ratio: el cociente \[ \Big({\frac{p_b}{1-p_b}}\Big)\Big/\Big({\frac{p_n}{1-p_n}}\Big). \]
4.8.2 Introducción a las odds
El odds de un suceso \(A\) es el cociente \[ \mbox{Odds}(A)=\frac{P(A)}{1-P(A)}, \] donde \(P(A)\) es la probabilidad que suceda \(A\) y mide cuántas veces es más probable \(A\) que su contrario.
Las odds son una función creciente de la probabilidad, y por lo tanto \[ \mbox{Odds}(A)<\mbox{Odds}(B)\Longleftrightarrow P(A)<P(B). \]
Esto permite comparar odds en vez de probabilidades, con la misma conclusión.
Por ejemplo, en nuestro caso, como el intervalo de confianza para la odds ratio va de 0.8723 a 5.1038. En particular, contiene el 1, por lo que no podemos rechazar que
\[ \Big({\frac{p_b}{1-p_b}}\Big)\Big/\Big({\frac{p_n}{1-p_n}}\Big)=1, \] es decir, no podemos rechazar que \[ \frac{p_b}{1-p_b}=\frac{p_n}{1-p_n} \] y esto es equivalente a \(p_b=p_n\).
Si, por ejemplo, el intervalo de confianza hubiera ido de 0 a 0.8, entonces la conclusión a este nivel de confianza hubiera sido que \[ \Big({\frac{p_b}{1-p_b}}\Big)\Big/\Big({\frac{p_n}{1-p_n}}\Big)<1 \] es decir, que \[ \frac{p_b}{1-p_b}<\frac{p_n}{1-p_n} \] y esto es equivalente a \(p_b<p_n\).
4.8.3 Contraste para dos proporciones: muestras grandes
Supongamos ahora que tenemos dos variables aleatorias \(X_1\) y \(X_2\) de Bernoulli de parámetros \(p_1\) y \(p_2\).
Consideremos una m.a.s. de cada variable aleatoria de tamaños \(n_1\) y \(n_2\), respectivamente, grandes (\(n_1,n_2\geq 50\) o 100): \[ \begin{array}{l} X_{1,1}, X_{1,2},\ldots, X_{1,n_1},\mbox{ de }X_1,\\ X_{2,1}, X_{2,2},\ldots, X_{2,n_2},\mbox{ de }X_2. \end{array} \] Sean \(\widehat{p}_1\) y \(\widehat{p}_2\) sus proporciones muestrales.
Suponemos que los números de éxitos y de fracasos en cada muestra son \(\geq 5\) o 10).
Nos planteamos los contrastes siguientes como en el caso del test de Fisher:
- \(\left\{\begin{array}{l} H_0:p_1=p_2,\\ H_1:p_1> p_2. \end{array}\right.\)
- \(\left\{\begin{array}{l} H_0:p_1=p_2,\\ H_1:p_1< p_2. \end{array}\right.\)
- \(\left\{\begin{array}{l} H_0:p_1=p_2,\\ H_1:p_1\neq p_2. \end{array}\right.\)
El estadístico de contraste para los contrastes anteriores es: \[Z=\frac{\widehat{p}_1 -\widehat{p}_2}{ \sqrt{\Big(\frac{n_1 \widehat{p}_1 +n_2 \widehat{p}_2}{n_1 +n_2}\Big)\Big(1-\frac{n_1 \widehat{p}_1 +n_2 \widehat{p}_2}{n_1 +n_2}\Big)\Big(\frac1{n_1}+\frac1{n_2} \Big)}},\] que, usando el Teorema Central del Límite y suponiendo cierta la hipótesis nula \(H_0:p_1=p_2\), tiene aproximadamente una distribución \(N(0,1)\).
Sea \(z_0\) el valor del estadístico de contraste usando las proporciones muestrales \(\widehat{p}_1\) y \(\widehat{p}_2\).
Los p-valores serán los siguientes:
- \(p\)-valor: \(P(Z\geq z_0)\).
- \(p\)-valor: \(P(Z\leq z_0)\).
- \(p\)-valor: \(2 P(Z \geq |z_0|)\).
Ejercicio
Se toman una muestra de ADN de 100 individuos con al menos tres generaciones familiares en la isla de Mallorca, y otra de 50 individuos con al menos tres generaciones familiares en la isla de Menorca.
Se quiere saber si un determinado alelo de un gen es presente con la misma proporción en las dos poblaciones.
En la muestra mallorquina, 20 individuos lo tienen, y en la muestra menorquina, 12.
Contrastar la hipótesis de igualdad de proporciones al nivel de significación \(0.05\), y calcular el intervalo de confianza para la diferencia de proporciones para este \(\alpha\).
Fijémonos que los tamaños de las muestras (100 y 50) son bastante grandes
El contraste pedido es el siguiente: \[ \left\{\begin{array}{l} H_0:p_1=p_2,\\ H_1:p_1\neq p_2, \end{array}\right. \] donde \(p_1\) y \(p_2\) representan las proporciones de individuos que tienen el alelo en el gen para los individuos de la isla de Mallorca y Menora, respectivamente.
El estadístico de contraste será: \(Z=\frac{\widehat{p}_1 -\widehat{p}_2}{ \sqrt{\Big(\frac{n_1 \widehat{p}_1 +n_2 \widehat{p}_2}{n_1 +n_2}\Big)\Big(1-\frac{n_1 \widehat{p}_1 +n_2 \widehat{p}_2}{n_1 +n_2}\Big)\Big(\frac1{n_1}+\frac1{n_2} \Big)}}.\)
Las proporciones muestrales serán: \(\widehat{p}_1 =\frac{20}{100}=0.2\), \(\widehat{p}_2 = \frac{12}{50}=0.24\).
Si hallamos el valor que toma el estadístico de contraste para las proporciones muestrales anteriores, obtenemos: \[z_0=\frac{0.2 -0.24}{ \sqrt{\Big(\frac{20+12}{100+50}\Big)\Big(1-\frac{20 +12}{100+50}\Big)\Big(\frac1{100}+\frac1{50}\Big)}}=-0.564.\]
El \(p\)-valor será: \(2\cdot P(Z\geq |-0.564|)=0.573.\)
Decisión: como el \(p\)-valor es grande y mayor que \(\alpha=0.05\), aceptamos la hipótesis que las dos proporciones son la misma al no tener evidencias suficientes para rechazarla.
El intervalo de confianza para \(p_1-p_2\) al nivel de confianza \((1-\alpha)\cdot 100\%\) en un contraste bilateral es \[ \begin{array}{l} \left(\widehat{p}_1-\widehat{p}_2-z_{1-\frac{\alpha}2}\sqrt{\Big(\frac{n_1 \widehat{p}_1 +n_2 \widehat{p}_2}{n_1 +n_2}\Big)\Big(1-\frac{n_1 \widehat{p}_1 +n_2 \widehat{p}_2}{n_1 +n_2}\Big)\Big(\frac1{n_1}+\frac1{n_2} \Big)},\right.\\ \quad \left.\widehat{p}_1-\widehat{p}_2+z_{1-\frac{\alpha}2}\sqrt{\Big(\frac{n_1 \widehat{p}_1 +n_2 \widehat{p}_2}{n_1 +n_2}\Big)\Big(1-\frac{n_1 \widehat{p}_1 +n_2 \widehat{p}_2}{n_1 +n_2}\Big)\Big(\frac1{n_1}+\frac1{n_2} \Big)} \right) \end{array} \] que, en nuestro caso será:
\[ (0.2 -0.24-1.96\cdot 0.071, 0.2-0.24 +1.96\cdot 0.071) =(-0.179,0.099). \] Observemos que contiene el 0. Por tanto no podemos rechazar que \(p_1-p_2=0\) llegando a la misma conclusión que con el \(p\)-valor.
- En
Restá implementado en la funciónprop.test, que además también sirve para contrastar dos proporciones por medio de muestras independientes grandes. Su sintaxis es
donde:
xen el caso de un contraste de dos proporciones es un vector de dos números naturales cuyas componentes son los números de éxitos en las dos muestras.Cuando estamos trabajando con dos muestras,
nes el vector de dos entradas de sus tamaños.El significado de
alternativeyconf.level, y sus posibles valores, son los usuales.
Ejemplo
Siguiendo el ejemplo anterior,
contrastemos otra vez si la proporción de madres fumadoras de raza blanca es la misma que la proporción de madres fumadoras de raza negra pero usando ahora la función prop.test.
En primer lugar, calculamos cuántas madres fumadores hay de cada muestra:
##
## 0 1
## 24 26##
## 0 1
## 33 17n.blanca = table(muestra.madres.raza.blanca$smoke)[2] ## número de madres fumadoras
## de raza blanca
n.negra = table(muestra.madres.raza.negra$smoke)[2] ## número de madres fumadoras
## de raza negraTenemos un total de 26 madres fumadoras de raza blanca entre las 50 de la muestra y 17 madres fumadores de raza negra entre las 50 de la muestra.
Finalmente, realizamos el contraste planteado: \[ \left. \begin{array}{ll} H_0: & p_b = p_n, \\ H_1: & p_b \neq p_n, \end{array} \right\} \] donde \(p_b\) y \(p_n\) representan las proporciones de madres fumadoras de raza blanca y negra, respectivamente.
El contraste en R se realizaría de la forma siguiente:
##
## 2-sample test for equality of proportions with continuity correction
##
## data: c(n.blanca, n.negra) out of c(50, 50)
## X-squared = 2.6, df = 1, p-value = 0.1
## alternative hypothesis: two.sided
## 95 percent confidence interval:
## -0.03083 0.39083
## sample estimates:
## prop 1 prop 2
## 0.52 0.34El p-valor del contraste ha sido 0.1061, muy parecido al del test de Fisher, y mayor que 0.1. Concluimos otra vez que no tenemos evidencias para rechazar que las proporciones de madres fumadoras de razas blanca y negra sean iguales.
Si nos fijamos en el intervalo de confianza para la diferencia de proporciones:
## [1] -0.03083 0.39083
## attr(,"conf.level")
## [1] 0.95vemos que el 0 está dentro de dicho intervalo, hecho que reafirma nuestra conclusión.
4.9 Contrastes de dos muestras más generales
Dado un parámetro \(\theta\) (\(\theta\) puede ser la media \(\mu\), la proporción \(p\), etc.) y dadas dos poblaciones \(X_1\) y \(X_2\) cuyas distribuciones dependen de parámetros \(\theta_1\) y \(\theta_2\), hemos realizado contrastes en los que la hipótesis nula era de la forma \(H_0:\theta_1 = \theta_2\), o \(H_0:\theta_1 - \theta_2=0\).
Existen contrastes más generales del tipo: \[ \left\{\begin{array}{l} H_0:\theta_1-\theta_2=\Delta\\ H_1:\theta_1-\theta_2<\Delta\mbox{ o }\theta_1-\theta_2>\Delta\mbox{ o }\theta_1-\theta_2\neq\Delta \end{array}\right. \] con \(\Delta\in \mathbb{R}\).
4.9.1 Cambios en los estadísticos de contraste
Para realizar los contrastes anteriores, se pueden usar los mismos estadísticos que en el caso en que \(H_0:\theta_1 - \theta_2=0\) realizando los cambios siguientes:
Si \(\theta =\mu\), la media, hay que sustituir \(\overline{X}_1-\overline{X}_2\) en el numerador del estadístico por \(\overline{X}_1-\overline{X}_2-\Delta\).
Si \(\theta =p\), proporción muestral, hay que sustituir \(\widehat{p}_1-\widehat{p}_2\) en el numerdor del estadístico por \(\widehat{p}_1-\widehat{p}_2-\Delta\).
Ejemplo
Tenemos dos tratamientos, A y B, de una dolencia. Tratamos 50 enfermos con A y 100 con B. 20 enfermos tratados con A y 25 tratados con B manifiestan haber sentido malestar general durante los 7 días posteriores a iniciar el tratamiento.
¿Podemos concluir, a un nivel de significación del 5%, que A produce malestar general en una proporción de los enfermos que es 5 puntos porcentuales superior a la proporción de los enfermos en que lo produce B?
Sean \(p_1\) la proporción de enfermos en que A produce malestar general y \(p_2\), la proporción de enfermos en que B produce malestar general.
El contraste a realizar es el siguiente: \[ \left\{\begin{array}{l} H_0:p_1\leq p_2+0.05,\\ H_1:p_1>p_2+0.05. \end{array}\right. \]
El estadístico de contraste es el siguiente: \[ Z=\frac{\widehat{p}_1 -\widehat{p}_2-\Delta}{ \sqrt{\Big(\frac{n_1 \widehat{p}_1 +n_2 \widehat{p}_2}{n_1 +n_2}\Big)\Big(1-\frac{n_1 \widehat{p}_1 +n_2 \widehat{p}_2}{n_1 +n_2}\Big)\Big(\frac1{n_1}+\frac1{n_2} \Big)}}, \] que, si la hipótesis nula es cierta, sigue aproximadamente la distribución \(N(0,1)\).
Las proporciones y los tamaños muestrales son: \(\widehat{p}_1=0.4\), \(\widehat{p}_2=0.25\), \(n_1=50\), \(n_2=100\) y el valor de \(\Delta\) será \(\Delta=0.05\).
El valor que toma el estadístico de contraste es: \[ z_0=\frac{0.4-0.25-0.05}{ \sqrt{\Big(\frac{20+25}{50+100}\Big)\Big(1-\frac{20+25}{50+100}\Big)\Big(\frac1{50}+\frac1{100}\Big)}}=1.26. \]
El \(p\)-valor del contraste será: \(P(Z\geq 1.26)= 0.104.\)
Decisión: como el \(p\)-valor es relativamente grande y mayor que \(\alpha=0.05\), no tenemos indicios para rechazar la hipótesis que \(p_1-p_2\) es inferior o igual a un \(5\%\).
Si hallamos el intervalo de confianza para \(p_1-p_2\) al nivel de confianza \((1-\alpha)\cdot 100\%\), obtenemos:
\[ \begin{array}{l} \left(\widehat{p}_1-\widehat{p}_2+z_{\alpha}\sqrt{\Big(\frac{n_1 \widehat{p}_1 +n_2 \widehat{p}_2}{n_1 +n_2}\Big)\Big(1-\frac{n_1 \widehat{p}_1 +n_2 \widehat{p}_2}{n_1 +n_2}\Big)\Big(\frac1{n_1}+\frac1{n_2} \Big)},\infty \right) = \\ \left(0.4-0.25 -1.645\sqrt{\left(\frac{50 \cdot 0.4 +100\cdot 0.25}{50 +100}\right)\left(1-\frac{50 \cdot 0.4 +100\cdot 0.25}{50 +100}\right)\left(\frac1{50}+\frac1{100}\right)},\infty\right) = \\ (0.019,\infty) \end{array} \]
Nos fijamos que el intervalo anterior contiene el valor \(\Delta =0.05\), razón que nos reafirma la decisión tomada de no rechazar que \(p_1\leq p_2+ 0.05\) pero, en cambio, no contiene el valor \(0\) y por tanto, podríamos rechazar que \(p_1=p_2\).
4.10 Contrastes para dos varianzas
Dadas dos poblaciones de distribución normal e indpendientes, nos planteamos si las varianzas de dichas poblaciones son iguales o diferentes.
Una aplicación del contraste de varianzas es decidir qué opción elegir en el marco de una comparación de medias de muestras independientes.
Tenemos dos variables aleatorias \(X_1\) y \(X_2\) normales de desviaciones típicas \(\sigma_1\), \(\sigma_2\) desconocidas
Suponemos que tenemos una m.a.s de cada variable: \[ \begin{array}{l} X_{1,1}, X_{1,2},\ldots, X_{1,n_1}\mbox{ de }X_1\\ X_{2,1}, X_{2,2},\ldots, X_{2,n_2}\mbox{ de }X_2 \end{array} \] Sean \(\widetilde{S}_1^2\) y \(\widetilde{S}_2^2\) sus varianzas muestrales.
Nos planteamos los contrastes siguientes:
- \(\left\{\begin{array}{l} H_0:\sigma_1=\sigma_2, \quad \left(\mbox{ o } H_0:\dfrac{\sigma_1^2}{\sigma_2^2}=1\right),\\ H_1:\sigma_1 > \sigma_2. \end{array} \right.\)
- \(\left\{\begin{array}{l} H_0:\sigma_1=\sigma_2, \quad \left(\mbox{ o } H_0:\dfrac{\sigma_1^2}{\sigma_2^2}=1\right),\\ H_1:\sigma_1 < \sigma_2. \end{array} \right.\)
- \(\left\{\begin{array}{l} H_0:\sigma_1=\sigma_2, \quad \left(\mbox{ o } H_0:\dfrac{\sigma_1^2}{\sigma_2^2}=1\right),\\ H_1:\sigma_1 \neq \sigma_2. \end{array} \right.\)
Se emplea el siguiente estadístico de contraste: \[ F=\frac{\widetilde{S}_1^2}{\widetilde{S}_2^2} \] que, si las dos poblaciones son normales y la hipótesis nula \(H_0:\sigma_1=\sigma_2\) es cierta, tiene distribución \(F\) de Fisher con grados de libertad \(n_1-1\) y \(n_2-1\).
Sea \(f_0\) el valor que toma usando las desviaciones típicas muestrales.
La distribución \(F_{n,m}\) de Fisher, donde \(n,m\) son los grados de libertad se define como el cociente de dos variables chi2 independientes de \(n\) y \(m\) grados de libertad, respectivamente: \({\chi_{n}^2}/{\chi_m^2}\).
Su función de densidad tiene la siguiente expresión: \[ f_{F_{n,m}}(x)=\frac{\Gamma\left(\frac{n+m}2\right)\cdot\left(\frac{m}{n}\right)^{m/2}x^{(m-2)/2}} {\Gamma\left(\frac{n}2\right)\Gamma\left(\frac{m}2\right)\left(1+\frac{m}{n}x\right)^{(m+n)/2}}, \mbox{ si $x\geq 0$,} \] donde \(\Gamma(x)=\int_0^{\infty} t^{x-1}e^{-t}\, dt,\) si \(x> 0\).
Se trata de una distribución no simétrica.
Gráfica de la función de densidad de algunas distribuciones \(F\) de Fisher.
Los \(p\)-valores asociados a los contrastes anteriores son:
- \(p\)-valor: \(P(F_{n_1-1,n_2-1}\geq f_0)\).
- \(p\)-valor: \(P(F_{n_1-1,n_2-1}\leq f_0)\).
- \(p\)-valor: \(\min\{2\cdot P(F_{n_1-1,n_2-1}\leq f_0),2\cdot P(F_{n_1-1,n_2-1}\geq f_0)\}\).
Ejercicio
Consideramos el ejemplo donde queríamos comparar los tiempos de realización de una tarea entre estudiantes de dos grados \(G_1\) y \(G_2\). Suponemos que estos tiempos siguen distribuciones normales.
Disponemos de dos muestras independientes de los tiempos usados por los estudiantes de cada grado para realizar la tarea. Los tamaños de cada muestra son \(n_1=n_2=40\).
Las desviaciones típicas muestrales de los tiempos empleados para cada muestra son: \[ \widetilde{S}_1=1.201,\quad \widetilde{S}_2=1.579 \]
Contrastar la hipótesis de igualdad de varianzas al nivel de significación \(0.05\).
El contraste planteado es el siguiente: \[ \left\{\begin{array}{l} H_0:\sigma_1=\sigma_2,\\ H_1:\sigma_1\neq \sigma_2, \end{array}\right. \] donde \(\sigma_1\) y \(\sigma_2\) son las desviaciones típicas de los tiempos empleados para realizar la tarea por los estudiantes de los grados \(G_1\) y \(G_2\), respectivamente.
El estadístico de contraste para el contraste anterior es: \(F=\frac{\widetilde{S}_1^2}{\widetilde{S}_2^2}\sim F_{39,39}\).
Dicho estadístico toma el siguiente valor: \(f_0=\frac{1.201^2}{1.579^2}=0.579.\)
El \(p\)-valor para el contraste anterior será: \[ \begin{array}{l} \min\{2\cdot P(F_{n_1-1,n_2-1}\leq f_0),2\cdot P(F_{n_1-1,n_2-1}\geq f_0)\}= \\ \min\{2\cdot P(F_{n_1-1,n_2-1}\leq 0.579),2\cdot P(F_{n_1-1,n_2-1}\geq 0.579)\} = \\ \min\{0.091,1.909\}=0.091. \end{array} \]
Decisión: como que el \(p\)-valor es moderado pero mayor que \(\alpha=0.05\), no podemos rechazar la hipótesis que las dos varianzas sean iguales.
Concluimos que no tenemos evidencias suficientes para rechazar que \(\sigma_1= \sigma_2\).
Por tanto, en el contraste de las dos medias, tendríamos que suponer que las varianzas de las dos poblaciones son la misma.
El intervalo de confianza para \(\frac{\sigma_1^2}{\sigma_2^2}\) al nivel de confianza \((1-\alpha)\cdot 100\%\) es \[ \left(\frac{\widetilde{S}_1^2}{\widetilde{S}_2^2}\cdot F_{n_1-1,n_2-1,\frac{\alpha}2},\frac{\widetilde{S}_1^2}{\widetilde{S}_2^2}\cdot F_{n_1-1,n_2-1,1-\frac{\alpha}2}\right) = \left(\frac{1.201^2}{1.579^2}\cdot F_{39,39,0.025},\frac{1.201^2}{1.579^2}\cdot F_{39,39,0.975}\right)=(0.306,1.094) \] Observemos que el intervalo de confianza anterior contiene el valor 1, hecho que reafirma la decisión tomada de no rechazar la hipótesis de igualdad de varianzas.
Ejemplo Se desea comparar la actividad motora espontánea de un grupo de 25 ratas control y otro de 36 ratas desnutridas. Se midió el número de veces que pasaban ante una célula fotoeléctrica durante 24 horas. Los datos obtenidos fueron los siguientes:
| \(n\) | \(\overline{X}\) | \(\widetilde{S}\) | |
|---|---|---|---|
| 1. Control | 25 | \(869.8\) | \(106.7\) |
| 2. Desnutridas | 36 | \(665\) | \(133.7\) |
¿Se observan diferencias significativas entre el grupo de control y el grupo desnutrido?
Supondremos que los datos anteriores provienen de poblaciones normales.
El contraste a realizar es el siguiente: \[ \left\{\begin{array}{l} H_0:\mu_1=\mu_2,\\ H_1:\mu_1\neq \mu_2, \end{array}\right. \] donde \(\mu_1\) y \(\mu_2\) representan los valores medios del número de veces que las ratas de control y desnutridas pasan ante la célula fotoeléctrica, respectivamente.
Antes de nada, tenemos que averiguar si las varianzas de los dos grupos son iguales o no ya que es un parámetro a usar en el contraste a realizar.
Por tanto, en primer lugar, realizaremos el contraste: \[ \left\{\begin{array}{l} H_0:\sigma_1=\sigma_2\\ H_1:\sigma_1\neq \sigma_2 \end{array}\right. \] donde \(\sigma_1\) y \(\sigma_2\) representan las desviaciones típicas del número de veces que las ratas de control y desnutridas pasan ante la célula fotoeléctrica, respectivamente.
El Estadístico de contraste para el contraste anterior vale: \(F=\frac{\widetilde{S}_1^2}{\widetilde{S}_2^2}\sim F_{24,35}.\)
El valor que toma es el siguiente: \(f_0=\frac{106.7^2}{133.7^2}=0.637.\)
El \(p\)-valor para el contraste anterior vale: \[ \begin{array}{l} \min\{2\cdot P(F_{n_1-1,n_2-1}\leq f_0),2\cdot P(F_{n_1-1,n_2-1}\geq f_0)\}= \\ \min\{2\cdot P(F_{n_1-1,n_2-1}\leq 0.637),2\cdot P(F_{n_1-1,n_2-1}\geq 0.637)\} = \\ \min\{0.251,1.749\}=0.251. \end{array} \] El \(p\)-valor es un valor grande, por tanto, concluimos que no podemos rechazar la hipótesis nula y decidimos que las varianzas de las dos poblaciones son iguales.
Realicemos a continuación el contraste pedido: \[ \left\{\begin{array}{l} H_0:\mu_1=\mu_2\\ H_1:\mu_1\neq \mu_2 \end{array}\right. \]
El estadístico de contraste al suponer que \(\sigma_1= \sigma_2\), será: \(T=\frac{\overline{X}_1-\overline{X}_2} {\sqrt{(\frac1{n_1}+\frac1{n_2})\cdot \frac{(n_1-1)\widetilde{S}_1^2+(n_2-1)\widetilde{S}_2^2} {n_1+n_2-2}}}\sim t_{59}\).
El valor que toma dicho estadístico en los valores muestrales vale: \(t_0=\frac{869.8-665}{\sqrt{(\frac1{25}+\frac1{36})\cdot \frac{24\cdot 106.7^2+35\cdot 133.7^2} {25+36-2}}}=6.373.\)
El \(p\)-valor del contraste será: \(p=2\cdot P(t_{59}\geq 6.373)\approx 0.\)
Decisión: como el \(p\)-valor es prácticamente nulo, concluimos que tenemos evidencias suficientes para rechazar la hipótesis nula y por tanto hay diferencias entre las ratas de control y las desnutridas entre el número de veces que pasan ante la célula fotoeléctrica.
4.10.1 Contrastes para varianzas en R
La función para efectuar este test en R es var.testy su sintaxis básica es la misma que la de t.test para dos muestras:
donde x e y son los dos vectores de datos, que se pueden especificar mediante una fórmula como en el caso de t.test, y el parámetro alternative puede tomar los tres mismos valores que en los tests anteriores.
Ejercicio
Recordemos que cuando explicábamos el contraste para dos medias independientes, contrastamos si las medias de las longitudes del pétalo para las especies setosa y versicolor eran iguales o no pero necesitábamos saber si las varianzas eran iguales o no para poder tenerlo en cuenta en la función t.test.
Veamos ahora si podemos considerar las varianzas iguales o no.
Las muestras eran muestra.setosa y muestra.versicolor.
Realicemos el contraste de igualdad de varianzas:
##
## F test to compare two variances
##
## data: muestra.setosa$Petal.Length and muestra.versicolor$Petal.Length
## F = 0.14, num df = 39, denom df = 39, p-value = 0.00000002
## alternative hypothesis: true ratio of variances is not equal to 1
## 95 percent confidence interval:
## 0.0758 0.2710
## sample estimates:
## ratio of variances
## 0.1433El p-valor del contraste ha sido prácticamente cero. Por tanto, concluimos que tenemos evidencias suficientes para afirmar que las varianzas de las longitudes del pétalo de las flores de las especies setosa y versicolor son diferentes.
Si nos fijamos en el intervalo de confianza en el cociente de varianzas \(\frac{\sigma^2_{{ setosa}}}{\sigma^2_{{versicolor}}}\),
## [1] 0.0758 0.2710
## attr(,"conf.level")
## [1] 0.95vemos que no contiene el valor 1, de hecho está a la izquierda de él. Este hecho nos hace reafirmar la conclusión anterior.
Para que el contraste anterior tenga sentido, hemos de suponer que las longitudes del pétalo de las flores de las especies setosa y versicolor siguen distribuciones normales.
Hemos insistido en que el test F solo es válido si las dos poblaciones cuyas varianzas comparamos son normales.
¿Qué podemos hacer si dudamos de su normalidad? Usar un test no paramétrico que no presuponga esta hipótesis.
Hay diversos tests no paramétricos para realizar contrastes bilaterales de dos varianzas. Aquí os recomendamos el test de Fligner-Killeen, implementado en la función
fligner.test.- Se aplica o bien a una
listformada por las dos muestras, o bien a una fórmula que separe un vector numérico en dos muestras por medio de un factor de dos niveles.
- Se aplica o bien a una
Realicemos el contraste previo de igualdad de varianzas usando el test no paramétrico anterior para ver si llegamos a la misma conclusión:
##
## Fligner-Killeen test of homogeneity of variances
##
## data: list(muestra.setosa$Petal.Length, muestra.versicolor$Petal.Length)
## Fligner-Killeen:med chi-squared = 22, df = 1, p-value = 0.000002Como el p-valor vuelve a ser insignificante, llegamos a la misma conclusión anterior: tenemos evidencias suficientes para afirmar que las varianzas de las longitudes del pétalo de las flores de las especies setosa y versicolor son diferentes.
La ventaja de este test es que no necesitamos la normalidad de las muestras, aunque su potencia, que explicaremos más adelante, sea inferior.
4.11 Muestras emparejadas
Las muestras consideradas hasta el momento se han supuesto independientes.
Un caso completamente diferente es cuando las dos muestras corresponden a los mismos individuos o a individuos emparejados por algún factor.
Ejemplos:
Se estudia el estado de una dolencia a los mismos individuos antes y después de un tratamiento.
Se mide la incidencia de cáncer en parejas de hermanos gemelos.
En estos casos, se habla de muestras emparejadas, o paired samples en inglés.
Para decidir si hay diferencias entre los valores de dos muestras emparejadas, el contraste más común consiste a calcular las diferencias de los valores de cada una de las parejas de muestras y realizar un contraste para averiguar si la media de las diferencias es 0.
4.11.1 Contrastes de medias de muestras emparejadas
En el caso de un contraste de muestras emparejadas, sean \(X_1\) y \(X_2\) las variables correspondientes y sean \[ \begin{array}{l} X_{1,1}, X_{1,2},\ldots, X_{1,n},\mbox{ de }X_1\\ X_{2,1}, X_{2,2},\ldots, X_{2,n},\mbox{ de }X_2 \end{array} \] las m.a.s. de cada una de las variables correspondientes a las dos muestras.
Fijémonos que, al ser la muestras emparejadas, los tamaños de las mismas deben ser iguales.
Consideramos la variable diferencia \(D=X_1-X_2\). La m.a.s. de \(D\) construida a partir de las muestras anteriores será: \[ D_1 =X_{1,1}-X_{2,1}, \ D_2=X_{1,2}-X_{2,2},\ldots, D_n=X_{1,n}-X_{2,n}. \]
Los contastes planteados son los siguientes:- \(\left\{\begin{array}{l} H_0:\mu_1=\mu_2,\\ H_1:\mu_1> \mu_2. \end{array}\right.\)
- \(\left\{\begin{array}{l} H_0:\mu_1=\mu_2,\\ H_1:\mu_1< \mu_2. \end{array}\right.\)
- \(\left\{\begin{array}{l} H_0:\mu_1=\mu_2,\\ H_1:\mu_1\neq \mu_2. \end{array}\right.\)
- \(\left\{\begin{array}{l} H_0:\mu_d=0,\\ H_1:\mu_d> 0. \end{array}\right.\)
- \(\left\{\begin{array}{l} H_0:\mu_d=0,\\ H_1:\mu_d< 0. \end{array}\right.\)
- \(\left\{\begin{array}{l} H_0:\mu_d=0,\\ H_1:\mu_d\neq 0. \end{array}\right.\)
O sea, hemos reducido un contraste de medias de dos muestras dependientes a un contraste de una sola media de una sola muestra.
A partir de aquí, podemos calcular los p-valores y los intervalos de confianza de los contrates anteriores usando las expresiones de los contrastes de una media de una sola media vistos anteriormente.
Ejemplo de medias emparejadas
Disponemos de dos algoritmos de alineamiento de proteínas. Los dos producen resultados de la misma calidad.
Estamos interesados en saber cuál de los dos algoritmos es más eficiente, en el sentido de tener un tiempo de ejecución más corto. Suponemos que dichos tiempos de ejecución siguen leyes normales.
Tomamos una muestra de proteínas y les aplicamos los dos algoritmos, anotando los tiempos de ejecución sobre cada proteína.
Los resultados obtenidos son:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| algoritmo 1 | 8.1 | 11.9 | 11.4 | 12.9 | 9.0 | 7.2 | 12.4 | 6.9 | 8.9 | 8.3 |
| algoritmo 2 | 6.9 | 6.7 | 8.3 | 8.6 | 18.9 | 7.9 | 7.4 | 8.7 | 7.9 | 12.4 |
| diferencias | 1.2 | 5.2 | 3.1 | 4.3 | -9.9 | -0.7 | 5.0 | -1.8 | 1.0 | -4.1 |
La media y la desviación típica muestrales de las difencias son \(\overline{d}=0.33,\) \(\tilde s_d = 4.715.\)
Queremos contrastar la igualdad de medias con el test que corresponda. Y si son diferentes, decidir cuál tiene mayor tiempo de ejecución.
O sea, queremos realizar el contraste siguiente: \[ \left\{\begin{array}{l} H_0:\mu_1=\mu_2,\\ H_1:\mu_1\neq \mu_2, \end{array}\right. \] donde \(\mu_1\) y \(\mu_2\) son los tiempos de ejecución de los algoritmos 1 y 2, respectivamente.
Escribimos el contraste anterior en función de \(\mu_d\), la media de las diferencias de los tiempos de ejecución entre los dos algoritmos: \[ \left\{\begin{array}{l} H_0:\mu_d=0,\\ H_1:\mu_d\neq 0. \end{array}\right. \]
El estadístico de contraste para el contraste anterior es \(T=\frac{\overline{d}}{\widetilde{S}_d/\sqrt{n}},\) que tiene distribución \(t_{n-1}=t_{9}\).
Dicho estadístico toma el siguiente valor usando los valores muestrales: \(t_0=\frac{0.33}{4.715/\sqrt{10}}=0.221.\)
El \(p\)-valor del contraste anterior será: \(p=2\cdot p(t_{9} > |0.221|) =0.83.\)
Es un valor grande. Por tanto, no tenemos evidencias suficientes para rechazar la hipótesis nula y concluimos que los tiempos de ejecución de los dos algoritmos es el mismo.
4.11.2 Contrastes para medias emparejadas en R. El test t
Recordemos la sintaxis básica del test t en R
donde el único parámetro para indicarle si las muestras son emparejadas o independientes es el parámetro paired:
con paired=TRUE indicamos que las muestras son emparejadas, y con paired=FALSE (que es su valor por defecto) que son independientes.
Ejercicio
Nos planteamos si la longitud del sépalo supera la longitud del pétalo para las flores de la especie virginica en la tabla de datos iris.
En este caso se trataría de un contraste de medias dependientes: \[ \left. \begin{array}{ll} H_0: & \mu_{{sépalo,virginica}} =\mu_{{pétalo,virginica}}, \\ H_1: & \mu_{{sépalo,virginica}} > \mu_{{pétalo,virginica}}, \end{array} \right\} \] donde \(\mu_{{sépalo,virginica}}\) y \(\mu_{{pétalo,virginica}}\) son las longitudes del sépalo y del pétalo de las flores de la especie virginica.
Para realizar dicho contraste, vamos a considerar una muestra de 40 flores de la especie virgínica y sobre las mismas flores calcular las longitudes del sépalo y del pétalo.
En primer lugar seleccionamos las flores de la muestra:
La muestra elegida será:
El contraste a realizar es el siguiente:
t.test(muestra.virginica$Sepal.Length,muestra.virginica$Petal.Length,
paired=TRUE,alternative="greater")##
## Paired t-test
##
## data: muestra.virginica$Sepal.Length and muestra.virginica$Petal.Length
## t = 22, df = 39, p-value <0.0000000000000002
## alternative hypothesis: true difference in means is greater than 0
## 95 percent confidence interval:
## 0.9051 Inf
## sample estimates:
## mean of the differences
## 0.98Vemos que el p-valor del contraste es prácticamente nulo, lo que nos hace concluir que tenemos evidencias suficientes para afirmar que la longitud del sépalo es superior a la longitud del pétalo para las flores de la especie virginica.
Fijémonos que la media de la diferencia entre las medias de las longitudes del sépalo y del pétalo vale 0.98, valor suficientemente alejado del cero para poder afirmar que la media de la longitud del sépalo es superior a la media de la longitud del pétalo.
El intervalo de confianza al 95% de confianza para la diferencia de medias asociado al contraste anterior vale:
t.test(muestra.virginica$Sepal.Length,muestra.virginica$Petal.Length,
paired=TRUE,alternative="greater")$conf.int## [1] 0.9051 Inf
## attr(,"conf.level")
## [1] 0.95intervalo que no contiene el cero y que está a la derecha del mismo, lo que nos hace reafirmar que tenemos evidencias suficientes para rechazar la hipótesis nula \(H_0\).
4.11.3 Contrastes de proporciones de muestras emparejadas
Supongamos que evaluamos dos características dicotómicas sobre una misma muestra de \(n\) sujetos. Resumimos los resultados obtenidos en la tabla siguiente:
\[ \begin{array}{r|c} & \ \mbox{Característica 1}\ \\ \mbox{Característica 2} &\ \ \, \mbox{Sí}\qquad \mbox{No}\\\hline \mbox{Sí} & \quad\ \ a \qquad \ \ \, b\quad \\ \mbox{No} & \quad\ \ c \qquad \ \ \, d\quad \end{array} \]
Se cumple \(a+b+c+d=n\). Esta tabla quiere decir, naturalmente, que \(a\) sujetos de la muestra tuvieron la característica 1 y la característica 2, que \(b\) sujetos de la muestra tuvieron la característica 2 y pero no tuvieron la característica 2, etc.
Vamos a llamar \(p_{1}\) a la proporción poblacional de individuos con la característica 1, y \(p_{2}\) a la proporción poblacional de individuos con la característica 2.
Queremos contrastar la hipótesis nula \(H_{0}:p_1=p_2\) contra alguna hipótesis alternativa. En este caso, no pueden usarse las funciones prop.test o fisher.test.
La solución es realizar el contraste bilateral: (o los unilaterales asociados) \[ \left\{\begin{array}{l} H_{0}:p_1=p_2,\\ H_{1}:p_1\neq p_2. \end{array}\right. \] Dicho contraste tiene sentido cuando \(n\) es grande y el número \(b+c\) de casos discordantes (en los que una característica da Sí y la otra da No) es razonablemente grande, pongamos \(\geq 20\).
El estadístico de contraste para el contraste anterior es \(Z=\frac{\frac{b}{n}-\frac{c}{n}}{\sqrt{\frac{b+c}{n^2}}}\), cuya distribución aproximada es una \(N(0,1)\). Sea \(z_0\) el valor que toma sobre los valores muestrales.
Por tanto el \(p\)-valor será: \(p=2\cdot p(Z > |z_0|)\).
Ejercicio
Hallar los \(p\)-valores para los contrastes unilaterales.
Ejemplo de proporciones emparejadas
Se toma una muestra de \(1000\) personas afectadas por migraña. Se les facilita un fármaco porque aligere los síntomas.
Después de la administración se les pregunta si han notado alivio en el dolor.
Al cabo de un tiempo se suministra a los mismos individuos un placebo y se les vuelve a preguntar si han notado o no mejora.
Nos preguntamos si es más efectivo el fármaco que el placebo en base a los resultados del estudio:
| Fármaco/Placebo | Si | No |
|---|---|---|
| Si | 300 | 62 |
| No | 38 | 600 |
El contraste que nos piden realizar es el siguiente: \[ \left\{\begin{array}{l} H_0:p_1=p_2\\ H_1:p_1> p_2 \end{array}\right. \] donde \(p_1\) y \(p_2\) representan las proporciones de gente que encuentra mejora con el fármaco y el placebo, respectivamente.
El estadístico de contraste para el contraste anterior es: \(Z=\frac{\frac{b}{n}-\frac{c}{n}}{\sqrt{\frac{b+c}{n^2}}}\), cuya distribución aproximada es una \(N(0,1)\), donde \(a=300\), \(b=62\), \(c=38\) y \(d=600\) en nuestro caso.
El valor que toma dicho estadístico es: \(z_0 = \frac{\frac{62}{1000}-\frac{38}{1000}}{\sqrt{\frac{62+38}{1000^2}}} =2.4.\)
Este contraste solo es válido cuando la muestra es grande y el número de casos discordantes \(b+d\) (100 en nuestro caso) es “bastante grande”, \(\geq 20\).
El \(p\)-valor para el contraste considerado es \(P(Z>2.4)=0.008,\) pequeño.
Por lo tanto, concluimos que tenemos evidencias suficientes para rechazar la hipótesis nula y poder afirmar que el fármaco es más efectivo que el placebo.
4.11.4 Contrastes para proporciones de muestras emparejadas en R
En R podemos usar el test de McNemar, que se lleva a cabo con la instrucción mcnemar.test. Su sintaxis básica es
donde X es la matriz \(\left(\begin{array}{cc} a & b\\ c& d \end{array}\right)\)
que corresponde a la tabla anterior.
Ejercicio
Usando la tabla de datos birthw del paquete MASS, vamos a ver si la proporción de madres fumadoras es la misma que la proporción de madres hipertensas.
Para ello, vamos a considerar una muestra de 30 madres y vamos a realizar el contraste correspondiente.
En primer lugar elegimos las madres y consideramos la muestra correspondiente:
set.seed(333)
madres.elegidas.prop.empar = sample(1:189,30,replace=TRUE)
muestra.madres.prop.empar = birthwt[madres.elegidas.prop.empar,]Seguidamente, calculamos la matriz para usar en el contraste:
##
## 0 1
## 0 16 3
## 1 10 1Fijémonos que dicha matriz no es correcta ya que \(a=1\), \(b=10\), \(c=3\) y \(d=16\). Arreglamos la matriz:
Comprobamos que es correcta:
## [,1] [,2]
## [1,] 1 10
## [2,] 3 16Por último, realizamos el contraste planteado:
##
## McNemar's Chi-squared test with continuity correction
##
## data: matriz.prop.empar
## McNemar's chi-squared = 2.8, df = 1, p-value = 0.1Hemos obtenido un p-valor de 0.0961, valor que está entre 0.05 y 0.1, la llamada zona de penumbra donde no se puede tomar una decisión clara.
Podemos decir, si consideramos que el p-valor es suficientemente grande, que no tenemos evidencias suficientes para aceptar que la proporción de madres fumadoras y con hipertensión sea diferente.
En otras palabras, no rechazamos la hipótesis nula \(H_0\).
Ahora bien, hay que tener en cuenta que el p-valor no es demasiado grande para tal conclusión.
Otra posibilidad para realizar un contraste de dos proporciones usando muestras emparejadas, que no requiere de ninguna hipótesis sobre los tamaños de las muestras, es usar de manera adecuada la función binom.test.
Para explicar este método, consideremos la tabla siguiente, donde ahora damos las probabilidades poblacionales de las cuatro combinaciones de resultados: \[ \begin{array}{r|c} & \ \mbox{Característica 1}\ \\ \mbox{Característica 2} &\quad \ \!\mbox{Sí}\qquad\quad\, \mbox{No}\quad \\\hline \mbox{Sí} & \quad \ p_{11} \qquad\quad p_{01}\quad \\ \mbox{No} & \quad \ p_{10} \qquad\quad p_{00}\quad \end{array} \]
De esta manera \(p_1=p_{11}+p_{10}\) y \(p_2=p_{11}+p_{01}\).
Entonces, \(p_1=p_2\) es equivalente a \(p_{10}=p_{01}\) y cualquier hipótesis alternativa se traduce en la misma desigualdad, pero para \(p_{10}\) y \(p_{01}\):
\(p_1\neq p_2\) es equivalente a \(p_{10}\neq p_{01}\);
\(p_1< p_2\) es equivalente a \(p_{10}< p_{01}\); y
\(p_1> p_2\) es equivalente a \(p_{10}> p_{01}\).
Por lo tanto podemos traducir el contraste sobre \(p_1\) y \(p_2\) al mismo contraste sobre \(p_{10}\) y \(p_{01}\).
La gracia ahora está en que si la hipótesis nula \(p_{10}=p_{01}\) es cierta, entonces, en el total de casos discordantes, el número de sujetos en los que la característica 1 da Sí y la característica 2 da No sigue una ley binomial con \(p=0.5\).
Por lo tanto, podemos efectuar el contraste usando un test binomial exacto tomando
como muestra los casos discordantes de nuestra muestra, de tamaño \(b+c\),
como éxitos los sujetos que han dado Sí en la característica 1 y No en la característica 2, de tamaño \(c\),
con proporción a contrastar \(p=0.5\) y con hipótesis alternativa la que corresponda.
La ventaja de este test es que su validez no requiere de ninguna hipótesis sobre los tamaños de las muestras. El inconveniente es que el intervalo de confianza que nos dará será para \(p_{10}/(p_{10}+p_{01})\), y no permite obtener un intervalo de confianza para la diferencia o el cociente de las probabilidades \(p_1\) y \(p_2\) de interés.
Ejercicio
Volvamos a realizar el contraste anterior usando este método.
Recordemos que la matriz de proporciones era:
## [,1] [,2]
## [1,] 1 10
## [2,] 3 16Por tanto, el tamaño de nuestra muestra será:
## [1] 13El número de éxitos será:
## [1] 3El contraste a realizar será:
##
## Exact binomial test
##
## data: éxitos and n
## number of successes = 3, number of trials = 13, p-value = 0.09
## alternative hypothesis: true probability of success is not equal to 0.5
## 95 percent confidence interval:
## 0.05038 0.53813
## sample estimates:
## probability of success
## 0.2308Vemos que el p-valor es parecido usando el método anterior y por tanto, las conclusiones son las mismas.
4.12 Guía rápida
Excepto en las que decimos lo contrario, todas las funciones para realizar contrastes que damos a continuación admiten los parámetros alternative, que sirve para especificar el tipo de contraste (unilateral en un sentido u otro o bilateral), y conf.level, que sirve para indicar el nivel de confianza \(1-\alpha\). Sus valores por defecto son contraste bilateral y nivel de confianza 0.95.
t.testrealiza tests t para contrastar una o dos medias (tanto usando muestras independientes como emparejadas). Aparte dealternativeyconf.level, sus parámetros principales son:mupara especificar el valor de la media que queremos contrastar en un test de una media.pairedpara indicar si en un contraste de dos medias usamos muestras independientes o emparejadas.var.equalpara indicar en un contraste de dos medias usando muestras independientes si las varianzas poblacionales son iguales o diferentes.
sigma.test, para realizar tests \(\chi^2\) para contrastar una varianza (o una desviación típica). Dispone de los parámetrossigmaysigmasqpara indicar, respectivamente, la desviación típica o la varianza a contrastar.var.test, para realizar tests F para contrastar dos varianzas (o dos desviaciones típicas).fligner.test, para realizar tests no paramétricos de Fligner-Killeen para contrastar dos varianzas (o dos desviaciones típicas). No dispone de los parámetrosalternative(solo sirve para contastes bilaterales) niconf.level(no calcula intervalos de confianza).binom.test, para realizar tests binomiales exactos para contrastar una proporción. Dispone del parámetroppara indicar la proporción a contrastar.prop.test, para realizar tests aproximados para contrastar una proporción o dos proporciones de poblaciones usando muestras independientes. También dispone del parámetroppara indicar la proporción a contrastar en un contraste de una proporción.fisher.test, para realizar tests exactos de Fisher para contrastar dos proporciones usando muestras independientes.mcnemar.test, para realizar tests bilaterales de McNemar para contrastar dos proporciones usando muestras emparejadas. No dispone de los parámetrosalternativeniconf.level.