Parte 2 Minimización de Costes
¡Felicidades por darlo todo en el primer caso de estudio! Pasemos a una IA nueva y más avanzada.
2.1 Caso Práctico: Minimización de Costes en el Consumo Energético de un Centro de Datos
2.1.1 Problema a resolver
En 2016, la IA DeepMind minimizó una gran parte del costo de Google al reducir la factura de enfriamiento del centro de datos de Google en 40% utilizando su modelo de IA DQN (Deep Q-Learning). En este caso práctico, haremos algo muy similar. Configuraremos nuestro propio entorno de servidor y construiremos una IA que controlará el enfriamiento / calentamiento del servidor para que se mantenga en un rango óptimo de temperaturas mientras se ahorra la máxima energía, minimizando así los costes. Y tal como lo hizo la IA de DeepMind, nuestro objetivo será lograr al menos un 40% de ahorro de energía.
2.1.1.1 Entorno a definir
Antes de definir los estados, las acciones y las recompensas, debemos explicar cómo funciona el servidor. Lo haremos en varios pasos. Primero, enumeraremos todos los parámetros y variables del entorno por los cuales se controla el servidor. Después de eso, estableceremos la suposición esencial del problema, en la cual nuestra IA dependerá para proporcionar una solución. Luego especificaremos cómo simularemos todo el proceso. Y eventualmente explicaremos el funcionamiento general del servidor y cómo la IA desempeña su papel.
Parámetros
- la temperatura atmosférica promedio durante un mes
- el rango óptimo de temperaturas del servidor, que será \([18^{\circ} \textrm{C}, 24^{\circ} \textrm{C}]\)
- la temperatura mínima del servidor por debajo de la cual no funciona, que será \(-20^{\circ} \textrm {C}\)
- la temperatura máxima del servidor por encima de la cual no funciona, que será de \(80^{\circ} \textrm {C}\)
- el número mínimo de usuarios en el servidor, que será 10
- el número máximo de usuarios en el servidor, que será de 100
- el número máximo de usuarios en el servidor que puede subir o bajar por minuto, que será 5
- la tasa mínima de transmisión de datos en el servidor, que será 20
- la velocidad máxima de transmisión de datos en el servidor, que será de 300
- la velocidad máxima de transmisión de datos que puede subir o bajar por minuto, que será 10
Variables:
- la temperatura del servidor en cualquier momento
- la cantidad de usuarios en el servidor en cualquier momento
- la velocidad de transmisión de datos en cualquier minuto
- la energía gastada por la IA en el servidor (para enfriarlo o calentarlo) en cualquier momento
- la energía gastada por el sistema de enfriamiento integrado del servidor que automáticamente lleva la temperatura del servidor al rango óptimo cada vez que la temperatura del servidor sale de este rango óptimo
Todos estos parámetros y variables serán parte de nuestro entorno de servidor e influirán en las acciones de la IA en el servidor.
A continuación, expliquemos los dos supuestos básicos del entorno. Es importante comprender que estos supuestos no están relacionados con la inteligencia artificial, sino que se utilizan para simplificar el entorno para que podamos centrarnos al máximo en la solución de inteligencia artificial.
Suposiciones:
Nos basaremos en los siguientes dos supuestos esenciales:
Supuesto 1: la temperatura del servidor se puede aproximar mediante Regresión lineal múltiple, mediante una función lineal de la temperatura atmosférica, el número de usuarios y la velocidad de transmisión de datos:
\[\textrm{temp. del server} = b_0 + b_1 \times \textrm{temp. atmosf.} + b_2 \times \textrm{n. de usuarios} + b_3 \times \textrm{ratio de trans. de datos} \]
donde \(b_0 \in \mathbb{R}\), \(b_1>0\), \(b_2>0\) y \(b_3>0\).
La razón de ser de este supuesto y la razón por la cual \(b_1>0\), \(b_2>0\) y \(b_3>0\) son fáciles de entender de entender. De hecho, tiene sentido que cuando la temperatura atmosférica aumenta, la temperatura del servidor aumenta. Además, cuanto más usuarios estén activos en el servidor, más gastará el servidor para manejarlos y, por lo tanto, mayor será la temperatura del servidor. Y finalmente, por supuesto, mientras más datos se transmitan dentro del servidor, más gastará el servidor para procesarlo y, por lo tanto, la temperatura más alta del servidor será. Y para fines de simplicidad, solo suponemos que estas correlaciones son lineales. Sin embargo, podría ejecutarse totalmente la misma simulación suponiendo que son cuadráticos o logarítmicos. Siéntete libre de retocar el modelo.
Finalmente, supongamos que después de realizar esta Regresión lineal múltiple, obtuvimos los siguientes valores de los coeficientes: \(b_0 = 0\), \(b_1 = 1\), \(b_2 = 1.25\) y \(b_3 = 1.25\). En consecuencia:
\[\textrm{temp. del server} = \textrm{temp. atmosf.} + 1.25 \times \textrm{n. de usuarios} + 1.25 \times \textrm{ratio de trans. de datos} \]
Supuesto 2: la energía gastada por un sistema (nuestra IA o el sistema de enfriamiento integrado del servidor) que cambia la temperatura del servidor de \(T_t\) a \(T_{t + 1}\) en 1 unidad de tiempo (aquí 1 minuto), se puede aproximar nuevamente mediante regresión mediante una función lineal del cambio absoluto de temperatura del servidor:
\[E_t = \alpha |\Delta T_t| + \beta = \alpha |T_{t+1} - T_t| + \beta\]
donde:
- \(E_t\) es la energía gastada por el sistema en el servidor entre los tiempos \(t\) y \(t +1\),
- \(\Delta T_t\) es el cambio de temperatura del servidor causado por el sistema entre los tiempos \(t\) y \(t +1\),
- \(T_t\) es la temperatura del servidor en el instante \(t\),
- \(T_{t + 1}\) es la temperatura del servidor en el instante \(t +1\),
- \(\alpha > 0\),
- y \(\beta \in \mathbb{R}\).
Nuevamente, expliquemos por qué tiene sentido intuitivamente hacer esta suposición con \(\alpha>0\). Eso es simplemente porque cuanto más se calienta la IA o se enfría el servidor, más gasta energía para hacer esa transferencia de calor. De hecho, por ejemplo, imaginemos que el servidor de repente tiene problemas de sobrecalentamiento y acaba de alcanzar \(80^{\circ}\) C, luego, dentro de una unidad de tiempo (1 minuto), la IA necesitará mucha más energía para que la temperatura del servidor vuelva a su temperatura óptima de \(24^{\circ}\) C que devolverlo a \(50^{\circ}\) C por ejemplo. Y de nuevo por razones de simplicidad, solo suponemos que estas correlaciones son lineales. Además (en caso de que te lo estés preguntado), ¿por qué tomamos el valor absoluto? Eso es simplemente porque cuando la IA enfría el servidor, \(T_{t + 1}<T_t\), entonces \(\Delta T <0\). Y, por supuesto, una energía siempre es positiva, por lo que tenemos que tomar el valor absoluto de \(\Delta T\).
Finalmente, para mayor simplicidad, también asumiremos que los resultados de la regresión son \(\alpha = 1\) y \(\beta = 0\), de modo que obtenemos la siguiente ecuación final basada en el supuesto 2:
\[\begin{equation*} E_t = |\Delta T_t| = |T_{t+1} - T_t| = \begin{cases} T_{t+1} - T_t & \textrm{si $T_{t+1} > T_t$, es decir, si el servidor se calienta} \\ T_t - T_{t+1} & \textrm{si $T_{t+1} < T_t$, es decir, si el servidor se enfria} \end{cases} \end{equation*}\]
Ahora, expliquemos cómo simularemos el funcionamiento del servidor con los usuarios y los datos que entran y salen.
Simulación
El número de usuarios y la velocidad de transmisión de datos fluctuarán aleatoriamente para simular un servidor real. Esto lleva a una aleatoriedad en la temperatura y la IA tiene que entender cuánta potencia de enfriamiento o calefacción tiene que transferir al servidor para no deteriorar el rendimiento del servidor y, al mismo tiempo, gastar la menor energía optimizando su transferencia de calor.
Ahora que tenemos la imagen completa, expliquemos el funcionamiento general del servidor y la IA dentro de este entorno.
Funcionamiento general:
Dentro de un centro de datos, estamos tratando con un servidor específico que está controlado por los parámetros y variables enumerados anteriormente. Cada minuto, algunos usuarios nuevos inician sesión en el servidor y algunos usuarios actuales cierran sesión, por lo tanto, actualizan el número de usuarios activos en el servidor. Igualmente, cada minuto se transmiten algunos datos nuevos al servidor, y algunos datos existentes se transmiten fuera del servidor, por lo tanto, se actualiza la velocidad de transmisión de datos que ocurre dentro del servidor. Por lo tanto, según el supuesto 1 anterior, la temperatura del servidor se actualiza cada minuto. Ahora, concéntrate, porque aquí es donde entenderás el gran papel que la IA tiene que jugar en el servidor. Dos posibles sistemas pueden regular la temperatura del servidor: la IA o el sistema de enfriamiento integrado del servidor. El sistema de enfriamiento integrado del servidor es un sistema no inteligente que automáticamente devolverá la temperatura del servidor a su temperatura óptima. Expliquemos esto con más detalles: cuando la temperatura del servidor se actualiza cada minuto, puede mantenerse dentro del rango de temperaturas óptimas (\([18^{\circ} \textrm{C}, 24^{\circ} \textrm{C}]\)), o salir de este rango. Si sale del rango óptimo, como por ejemplo \(30^{\circ}\) C, el sistema de enfriamiento integrado del servidor llevará automáticamente la temperatura al límite más cercano del rango óptimo, que es \(24^{\circ}\) C. Sin embargo, el sistema de enfriamiento integrado de este servidor lo hará solo cuando la IA no esté activada. Si la IA está activada, en ese caso el sistema de enfriamiento integrado del servidor se desactiva y es la IA la que actualiza la temperatura del servidor para regularlo de la mejor manera. Pero la IA hace eso después de algunas predicciones previas, no de una manera determinista como con el sistema de enfriamiento integrado del servidor no inteligente. Antes de que haya una actualización de la cantidad de usuarios y la velocidad de transmisión de datos que hace que cambie la temperatura del servidor, la IA predice si debería enfriar el servidor, no hacer nada o calentar el servidor. Entonces ocurre el cambio de temperatura y la IA reitera. Y dado que estos dos sistemas son complementarios, los evaluaremos por separado para comparar su rendimiento.
Y eso nos lleva a la energía. De hecho, recordemos que un objetivo principal de la IA es ahorrar algo de energía gastada en este servidor. En consecuencia, nuestra IA tiene que gastar menos energía que la energía gastada por el sistema de enfriamiento no inteligente en el servidor. Y dado que, según el supuesto 2 anterior, la energía gastada en el servidor (por cualquier sistema) es proporcional al cambio de temperatura dentro de una unidad de tiempo:
\[\begin{equation*} E_t = |\Delta T_t| = \alpha |T_{t+1} - T_t| = \begin{cases} T_{t+1} - T_t & \textrm{si $T_{t+1} > T_t$, es decir, si el servidor se calienta} \\ T_t - T_{t+1} & \textrm{if $T_{t+1} < T_t$, es decir, si el servidor se enfria} \end{cases} \end{equation*}\]
entonces eso significa que la energía ahorrada por la IA en cada instante \(t\) (cada minuto) es, de hecho, la diferencia en los cambios absolutos de temperatura causados en el servidor entre el sistema de enfriamiento integrado del servidor no inteligente y la IA de \(t\) y \(t + 1\):
\[\begin{align*} \textrm{Energia ahorrada por la IA entre $t$ y $t+1$} & = |\Delta T_t^{\textrm{Sistema de Enfriamiento Integrado del Servidor}}| - |\Delta T_t^{\textrm{IA}}| \\ & = |\Delta T_t^{\textrm{no IA}}| - |\Delta T_t^{\textrm{IA}}| \end{align*}\]
donde:
- \(\Delta T_t^{\textrm{no IA}}\) es el cambio de temperatura que causaría el sistema de enfriamiento integrado del servidor sin la IA en el servidor durante la iteración \(t\), es decir, del instante \(t\) al instante \(t + 1\),
- \(\Delta T_t^{\textrm{AI}}\) es el cambio de temperatura causado por la IA en el servidor durante la iteración \(t\), es decir, del instante \(t\) al instante \(t + 1\).
Nuestro objetivo será ahorrar la energía máxima cada minuto, por lo tanto, ahorrar la energía total máxima durante 1 año completo de simulación y, finalmente, ahorrar los costos máximos en la factura de electricidad de refrigeración / calefacción.
¿Estamos preparados?
¡Excelente! Ahora que entendemos completamente cómo funciona nuestro entorno de servidor y cómo se simula, es hora de proceder con lo que debe hacerse absolutamente al definir un entorno de IA:
- Definir los estados
- Definir las acciones
- Definir las recompensas
Definir los estados
El estado de entrada \(s_t\) en el momento \(t\) se compone de los siguientes tres elementos:
- La temperatura del servidor en el instante \(t\).
- El número de usuarios en el servidor en el instante \(t\).
- La velocidad de transmisión de datos en el servidor en el instante \(t\).
Por lo tanto, el estado de entrada será un vector de entrada de estos tres elementos. Nuestra futura IA tomará este vector como entrada y devolverá la acción para ejecutar en cada instante \(t\).
Definir las acciones
Las acciones son simplemente los cambios de temperatura que la IA puede causar dentro del servidor, para calentarlo o enfriarlo. Para que nuestras acciones sean discretas, consideraremos 5 posibles cambios de temperatura de \(-3^{\circ}\) C a \(+ 3^{\circ}\) C, para que terminemos con las 5 acciones posibles que la IA puede llevar a cabo para regular la temperatura del servidor:
| Acción | ¿Qué hace? |
|---|---|
| 0 | La IA enfría el servidor \(3^{\circ}\)C |
| 1 | La IA enfría el servidor \(1.5^{\circ}\)C |
| 2 | La IA no transfiere calor ni frio al servidor (sin cambio de temperatura) |
| 3 | La IA calienta el servidor \(1.5^{\circ}\)C |
| 4 | La IA calienta el servidor \(3^{\circ}\)C |
Definir las recompensas.
Después de leer el párrafo “Funcionamiento general” anterior, puedes adivinar cuál será la recompensa. Por supuesto, la recompensa en la iteración \(t\) es la energía gastada en el servidor que la IA está ahorrando con respecto al sistema de enfriamiento integrado del servidor, es decir, la diferencia entre la energía que gastaría el sistema de enfriamiento no inteligente si la IA fuera desactivada y la energía que la IA gasta en el servidor:
\[\textrm{Reward}_t = E_t^{\textrm{no IA}} - E_t^{\textrm{IA}}\]
Y como (Supuesto 2), la energía gastada es igual al cambio de temperatura causado en el servidor (por cualquier sistema, incluido el AI o el sistema de enfriamiento no inteligente):
\[\begin{equation*} E_t = |\Delta T_t| = \alpha |T_{t+1} - T_t| = \begin{cases} T_{t+1} - T_t & \textrm{si $T_{t+1} > T_t$, es decir, si el servidor se calienta} \\ T_t - T_{t+1} & \textrm{si $T_{t+1} < T_t$, es decir, si el servidor se enfria} \end{cases} \end{equation*}\]
entonces obtenemos que la recompensa recibida en el instante \(t\) es, de hecho, la diferencia en el cambio de temperatura causada en el servidor entre el sistema de enfriamiento no inteligente (es decir, cuando no hay IA) y la IA:
\[\begin{align*} \textrm{Reward}_t & = \textrm{Energía ahorrada por la IA entre $t$ y $t+1$} \\ & = E_t^{\textrm{no IA}} - E_t^{\textrm{IA}} \\ & = |\Delta T_t^{\textrm{no IA}}| - |\Delta T_t^{\textrm{IA}}| \end{align*}\]
donde:
- \(\Delta T_t^{\textrm{no IA}}\) es el cambio de temperatura que causaría el sistema de enfriamiento integrado del servidor sin la IA en el servidor durante la iteración \(t\), es decir, del instante \(t\) al instante \(t + 1\),
- \(\Delta T_t^{\textrm{AI}}\) es el cambio de temperatura causado por la IA en el servidor durante la iteración \(t\), es decir, del instante \(t\) al instante \(t + 1\).
Nota importante: es importante comprender que los sistemas (nuestra IA y el sistema de enfriamiento del servidor) se evaluarán por separado para calcular las recompensas. Y dado que cada vez que sus acciones conducen a temperaturas diferentes, tendremos que realizar un seguimiento por separado de las dos temperaturas \(T_t^{\textrm{IA}}\) and \(T_t^{\textrm{no IA}}\).
Ahora, para terminar esta sección, vamos a hacer una pequeña simulación de 2 iteraciones (es decir, 2 minutos), como un ejemplo que hará que todo quede claro.
Ejemplo de simulación final.
Digamos que estamos en el instante de tiempo \(t = 4:00\) pm y que la temperatura del servidor es \(T_t = 28^\circ\) C, tanto con la IA como sin la IA. En este momento exacto, la IA predice la acción 0, 1, 2, 3 o 4. Desde ahora, la temperatura del servidor está fuera del rango de temperatura óptimo \([18^{\circ} \textrm{C}, 24^{\circ} \textrm{C }]\), la IA probablemente predecirá las acciones 0, 1 o 2. Digamos que predice 1, lo que corresponde a enfriar el servidor en \(1.5^{\circ}\) C. Por lo tanto, entre \(t = 4:00\) pm y \(t + 1 = 4: 01\) pm, la IA hace que la temperatura del servidor pase de \(T_t^{\textrm{IA}} = 28^{\circ} \textrm{C}\) a \(T_{t + 1}^{\ textrm{IA}} = 26.5^{\circ} \textrm{C}\):
\[\begin{align*} \Delta T_t^{\textrm{IA}} & = T_{t+1}^{\textrm{IA}} - T_t^{\textrm{IA}} \\ & = 26.5 - 27 \\ & = -1.5^{\circ} \textrm{C} \end{align*}\]
Por lo tanto, según el supuesto 2, la energía gastada por la IA en el servidor es:
\[\begin{align*} E_t^{\textrm{IA}} & = |\Delta T_t^{\textrm{IA}}| \\ & = 1.5 \ \textrm{Joules} \end{align*}\]
Bien, ahora solo falta una información para calcular la recompensa: es la energía que el sistema de enfriamiento integrado del servidor habría gastado si la IA se hubiera desactivado entre las 4:00 p.m. y las 4:01 p.m. Recordemos que este sistema de enfriamiento no inteligente lleva automáticamente la temperatura del servidor de vuelta al límite más cercano del rango de temperatura óptimo \([18^{\circ} \textrm{C}, 24^{\circ} \textrm{C}]\). Entonces, dado que a \(t = 4: 00 ¡\) pm la temperatura era \(T_t = 28^{\circ}\) C, entonces el límite más cercano del rango de temperatura óptimo en ese momento era \(24^{\circ}\) C. Por lo tanto, el sistema de enfriamiento integrado del servidor habría cambiado la temperatura de \(T_t = 28^{\circ} \textrm{C}\) a \(T_{t + 1} = 24^{\circ} \textrm{C}\), y por lo tanto la temperatura del servidor cambia habría ocurrido si no hubiera IA es:
\[\begin{align*} \Delta T_t^{\textrm{no IA}} & = T_{t+1}^{\textrm{no IA}} - T_t^{\textrm{no IA}} \\ & = 24 - 28 \\ & = -4^{\circ} C \end{align*}\]
Por lo tanto, según el supuesto 2, la energía que el sistema de enfriamiento no inteligente habría gastado si no hubiera IA es:
\[\begin{align*} E_t^{\textrm{no IA}} & = |\Delta T_t^{\textrm{no IA}}| \\ & = 4 \ \textrm{Joules} \end{align*}\]
En conclusión, la recompensa que obtenemos después de llevar a cabo esta acción en el momento \(t = 4: 00\) pm es:
\[\begin{align*} \textrm{Reward} & = E_t^{\textrm{no IA}} - E_t^{\textrm{IA}} \\ & = 4 - 1.5 \\ & = 2.5 \end{align*}\]
Luego, entre \(t = 4: 00\) pm y \(t + 1 = 4: 01\) pm, suceden otras cosas: algunos usuarios nuevos inician sesión en el servidor, algunos usuarios existentes cierran sesión en el servidor, algunos datos nuevos son transmitiendo dentro del servidor, y algunos datos existentes se transmiten fuera del servidor. Según el supuesto 1, estos factores hacen que la temperatura del servidor cambie. Digamos que aumentan la temperatura del servidor en \(5^{\circ}\) C:
\[\Delta_t \ \textrm{Temperatura Intrinseca} = 5^{\circ} C\]
Ahora recuerde que estamos evaluando dos sistemas por separado: nuestra IA y el sistema de enfriamiento integrado del servidor. Por lo tanto, debemos calcular por separado las dos temperaturas que obtendríamos con estos dos sistemas a \(t + 1 = 4: 01\) pm. Comencemos con la IA.
La temperatura que obtenemos en \(t + 1 = 4: 01\) pm cuando se activa la IA es:
\[\begin{align*} T_{t+1}^{\textrm{IA}} & = T_t^{\textrm{IA}} + \Delta T_t^{\textrm{IA}} + \Delta_t \ \textrm{Temperatura Intrinseca} \\ & = 28 + (-1.5) + 5 \\ & = 31.5^{\circ} C \end{align*}\]
Y la temperatura que obtenemos en \(t + 1 = 4: 01\) pm cuando la IA no está activada es:
\[\begin{align*} T_{t+1}^{\textrm{no IA}} & = T_t^{\textrm{no IA}} + \Delta T_t^{\textrm{no IA}} + \Delta_t \ \textrm{Temperatura Intrinseca} \\ & = 28 + (-4) + 5 \\ & = 29^{\circ} C \end{align*}\]
Perfecto, tenemos nuestras dos temperaturas separadas, que son \(T_{t+1}^{\textrm{AI}} = 29.5^{\circ} C\) cuando la IA está activada, y \(T_{t+1}^{\textrm{noAI}} = 27^{\circ} C\) cuando la IA no está activada.
Ahora simulemos lo que sucede entre los instantes \(t + 1 = 4:01\) pm y \(t + 2 = 4:02\) pm. Nuevamente, nuestra IA hará una predicción, y dado que el servidor se está calentando, digamos que predice la acción 0, que corresponde a enfriar el servidor en \(3^{\circ} C\), reduciéndolo a \(T_{t + 2}^{\textrm{IA}} = 28.5^{\circ} C\). Por lo tanto, la energía gastada por la IA entre \(t + 1 = 4: 01\) pm y \(t + 2 = 4: 02\) pm, es:
\[\begin{align*} E_{t+1}^{\textrm{IA}} & = |\Delta T_{t+1}^{\textrm{IA}}| \\ & = |28.5 - 31.5| \\ & = 3 \ \textrm{Joules} \end{align*}\]
Ahora con respecto al sistema de enfriamiento integrado del servidor (es decir, cuando no hay IA), ya que a \(t + 1 = 4: 01\) pm teníamos \(T_{t + 1}^{\textrm{no IA}} = 29^{\circ} C\), entonces el límite más cercano del rango óptimo de temperaturas sigue siendo \(24^{\circ} C\), por lo que la energía que el sistema de enfriamiento no inteligente del servidor gastaría entre \(t + 1 = 4: 01\) pm y \(t + 2 = 4 : 02\) pm, es:
\[\begin{align*} E_{t+1}^{\textrm{no IA}} & = |\Delta T_{t+1}^{\textrm{no IA}}| \\ & = |24 - 29| \\ & = 5 \ \textrm{Joules} \end{align*}\]
De ahí la recompensa obtenida entre \(t+1 = 4:01\) pm y \(t+2 = 4:02\) pm, es:
\[\begin{align*} \textrm{Reward} & = E_{t+1}^{\textrm{no IA}} - E_{t+1}^{\textrm{IA}} \\ & = 5 - 3 \\ & = 2 \end{align*}\]
Y finalmente, la recompensa total obtenida entre \(t = 4:00\) pm y \(t+2 = 4:02\) pm, es:
\[\begin{align*} \textrm{Total Reward} & = (\textrm{Recompensa obtenida entre $t$ y $t+1$}) + (\textrm{Recompensa obtenida entre $t+1$ y $t+2$}) \\ & = 2.5 + 2 \\ & = 4.5 \end{align*}\]
Ese fue un ejemplo de todo el proceso que sucedió en dos minutos. En nuestra implementación, ejecutaremos el mismo proceso durante 1000 épocas de 5 meses para el entrenamiento del algoritmo, y luego, una vez que nuestra IA esté entrenada, ejecutaremos el mismo proceso durante 1 año completo de simulación para la prueba. El entrenamiento se realizará con Deep Q-Learning, y aquí es donde entra en juego la siguiente sección.
2.2 Solución de IA
La solución de IA que resolverá el problema descrito anteriormente es un modelo Deep Q-Learning. Vamos a dar la teoría y las ecuaciones matemáticas detrás de esto.
2.2.1 Q-Learning en Deep Learning
El Deep Q-Learning consiste en combinar Q-Learning con una red neuronal artificial. Las entradas son vectores codificados, cada uno de los cuales define un estado del entorno. Estas entradas van a una red neuronal artificial, donde la salida es la acción a ejecutar. Más precisamente, digamos que el sistema tiene \(n\) acciones posibles, la capa de salida de la red neuronal está compuesta por \(n\) neuronas de salida, cada una correspondiente a los valores Q de cada acción que se juega en el estado actual. Entonces, la acción que se juega es la asociada con la neurona de salida que tiene el valor Q más alto (argmax), o la que devuelve el método softmax. En nuestro caso usaremos argmax. Y dado que los valores Q son números reales, eso hace que nuestra red neuronal sea un RNA para la regresión.
Así que, para cada estado \(s_t\):
- la predicción es el valor Q, \(Q (s_t, a_t)\) donde \(a_t\) es elegido por argmax o softmax,
- el valor objetivo es \(r_t + \gamma \underset{a}{\max}(Q(s_{t+1}, a))\),
- el error de pérdida entre la predicción y el objetivo es el cuadrado de la diferencia temporal:
\[\textrm{Loss} = \frac{1}{2} \left( r_t + \gamma \underset{a}{\max}(Q(s_{t+1}, a)) - Q(s_t, a_t) \right)^2 = \frac{1}{2} TD_t(s_t, a_t)^2.\]
Luego, este error de pérdida se propaga hacia atrás en la red, y los pesos se actualizan de acuerdo con la cantidad que contribuyeron al error.
2.2.2 Experience Replay
Notemos que hasta ahora solo hemos considerado las transiciones de un estado \(s_t\) al siguiente estado \(s_{t + 1}\). El problema con esto es que \(s_t\) está casi siempre muy correlacionado con \(s_{t + 1}\). Por lo tanto, la red no está aprendiendo mucho. Esto podría mejorarse mucho si, en lugar de considerar solo esta transición anterior, consideramos las últimas m transiciones donde m es un gran número. Este paquete de las últimas m transiciones es lo que se llama Experience Replay o repetición de experiencia. Luego, a partir de esta repetición de experiencia, tomamos algunos bloques aleatorios de transiciones para realizar nuestras actualizaciones.
2.2.3 El cerebro
El cerebro, o más precisamente la red neuronal profunda de nuestra IA, será una red neuronal completamente conectada, compuesta de dos capas ocultas, la primera con 64 neuronas y la segunda con 32 neuronas. Y como recordatorio, esta red neuronal toma como entradas los estados del entorno y devuelve como salidas los valores Q para cada una de las 5 acciones. Este cerebro artificial se entrenará con una pérdida de “error cuadrático medio” y un optimizador Adam.
Así es como se ve este cerebro artificial:
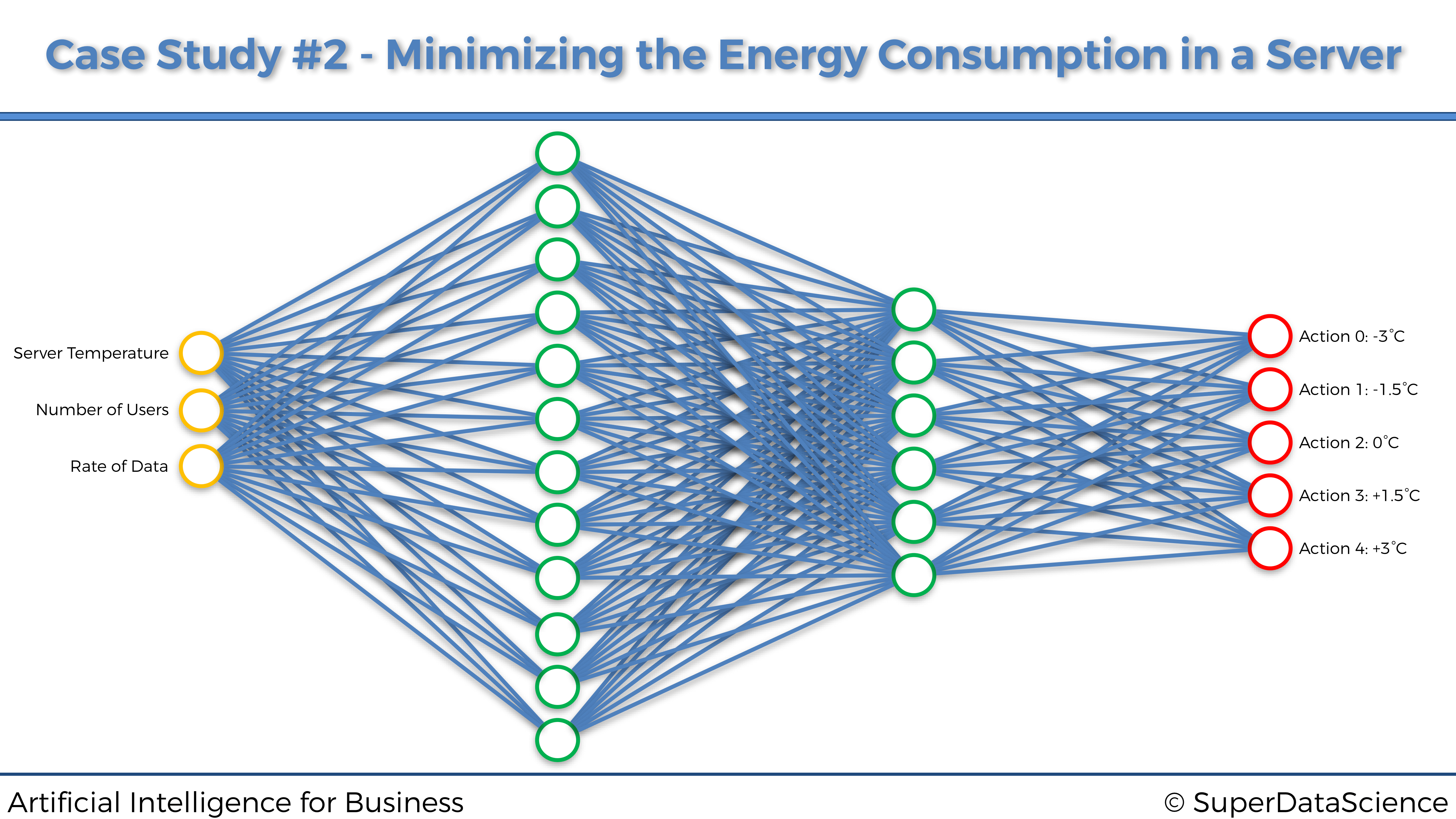
El cerebro artificial: una red neuronal completamente conectada
Este cerebro artificial parece complejo de crear, pero lo construiremos muy fácilmente gracias a la increíble librería de Keras. Aquí hay una vista previa de la implementación completa que contiene la parte que construye este cerebro por sí mismo:
# Construcción del cerebro
class Brain(object):
def __init__(self, learning_rate = 0.001, number_actions = 11):
self.learning_rate = learning_rate
states = Input(shape = (3,))
x = Dense(units = 64, activation = 'sigmoid')(states)
y = Dense(units = 32, activation = 'sigmoid')(x)
q_values = Dense(units = number_actions, activation = 'softmax')(y)
self.model = Model(inputs = states, outputs = q_values)
self.model.compile(loss = 'mse',
optimizer = Adam(lr = self.learning_rate))Como podemos ver con gusto, solo son necesarias un par de líneas de código.
2.2.4 El algoritmo de Deep Q-Learning al completo
Resumamos los diferentes pasos de todo el proceso de Deep Q-Learning:
Inicialización
La memoria de Experience Replay se inicializa en una lista vacía \(M\).
Elegimos un tamaño máximo de la memoria. En nuestro caso práctico elegimos un tamaño máximo de 100 transiciones.
Comenzamos en un primer estado, correspondiente a un momento específico dentro del año.
En cada instante \(t\), repetimos el siguiente proceso, hasta el final de la época (5 meses en nuestra implementación)
- Predecimos los valores Q del estado actual \(s_t\).
- Ejecutamos la acción que corresponde al máximo de estos valores Q predichos (método argmax): \[a_t = \underset{a}{\textrm{argmax}} Q(s_t, a)\]
- Obtenemos la recompensa:
\[r_t = E_t^{\textrm{no IA}} - E_t^{\textrm{IA}}\]
Alcanzamos el siguiente estado\(s_{t+1}\).
Añadimos la transición actual \((s_t, a_t, r_t, s_{t+1})\) a \(M\).
Seleccionamos un bloque de transiciones al azar \(B \subset M\). Para todas las transiciones\((s_{t_B}, a_{t_B}, r_{t_B}, s_{t_B+1})\) del bloquealeatorio \(B\):
- Obtenemos las predicciones: \[Q(s_{t_B}, a_{t_B})\]
- Obtenemos los objetivos: \[r_{t_B} + \gamma \underset{a}{\max}(Q(s_{t_B+1}, a))\]
- Calculamos la pérdida entre las predicciones y los objetivos en todo el bloque\(B\): \[\textrm{Loss} = \frac{1}{2} \sum_B \left( r_{t_B} + \gamma \underset{a}{\max}(Q(s_{t_B+1}, a)) - Q(s_{t_B}, a_{t_B}) \right)^2 = \frac{1}{2} \sum_B TD_{t_B}(s_{t_B}, a_{t_B})^2\]
- Volvemos a propagar este error de pérdida en la red neuronal y, a través del descenso de gradiente estocástico, actualizamos los pesos según cuánto contribuyeron al error..
2.3 Implementation
Esta implementación se dividirá en 5 partes, cada parte con su propio archivo de Python. Estas 5 partes constituyen el algoritmo general de IA, o Blueprint de la AI, que debe seguirse cada vez que construimos un entorno para resolver cualquier problema comercial con Deep Reinforcement Learning.
Aquí están, del Paso 1 al Paso 5:
- Construcción del entorno.
- Construcción del cerebro.
- Implementación del algoritmo de aprendizaje por refuerzo profundo (en nuestro caso será el modelo DQN).
- Entrenar a la IA.
- Probar de la IA.
Estos son los pasos principales (en ese mismo orden) de la sección de teoría general de IA anterior. Implementemos así nuestra IA para nuestro caso práctico específico, siguiendo este plan de IA, en las siguientes cinco secciones correspondientes a estos cinco pasos principales. Además en cada paso, distinguiremos los subpasos que todavía forman parte del algoritmo general de AI, de los subpasos que son específicos de nuestro caso práctico, escribiendo los títulos de las secciones de código en mayúsculas para todos los subpasos del algoritmo general de AI, y en letras mínimas para todos los subpasos específicos de nuestro caso práctico. Eso significa que cada vez que veamos una nueva sección de código cuyo título está escrito en letras mayúsculas, entonces es el siguiente subpaso del algoritmo general de IA, que también se debe seguir al crear una IA para cualquier otro problema comercial.
Así que ahora aquí vamos con el comienzo del viaje: Paso 1 - Construcción el entorno.
Este es el archivo de implementación de python más grande de este caso práctico, y del curso. Por lo tanto, asegúrete de descansar antes, recargar las baterías para obtener un buen nivel de energía y, tan pronto como estés listo, ¡abordemos esto juntos!
2.3.1 Paso 1: Construcción del Entorno
En este primer paso, vamos a construir el entorno dentro de una clase. ¿Por qué una clase? Porque nos gustaría tener nuestro entorno como un objeto que podamos crear fácilmente con cualquier valor de algunos parámetros que elijamos. Por ejemplo, podemos crear un objeto de entorno para un servidor que tenga un cierto número de usuarios conectados y una cierta velocidad de datos en un momento específico, y otro objeto de entorno para otro servidor que tenga un número diferente de usuarios conectados y un número diferente tasa de datos en otro momento. Y gracias a esta estructura avanzada de la clase, podemos conectar y reproducir fácilmente los objetos del entorno que creamos en diferentes servidores que tienen sus propios parámetros, por lo tanto, regulamos sus temperaturas con varias IA diferentes, de modo que terminamos minimizando el consumo de energía. de un centro de datos completo, tal como lo hizo la DeepMind de Google para los centros de datos de Google con su algoritmo DQN.
Esta clase sigue los siguientes subpasos, que son parte del algoritmo general de IA dentro del Paso 1: construcción del entorno:
- Paso 1-1: Introducción e inicialización de todos los parámetros y variables del entorno.
- Paso 1-2: Hacer un método que actualice el entorno justo después de que la IA ejecute una acción.
- Paso 1-3: Hacer un método que restablezca el entorno.
- Paso 1-4: hacer un método que nos proporcione en cualquier momento el estado actual, la última recompensa obtenida y si el juego ha terminado.
Encontrarás toda la implementación de esta clase de creación de entorno en las próximas páginas. Recuerda lo más importante: todas las secciones de código que tienen sus títulos escritos en letras mayúsculas son los pasos del framework de IA o del Blueprint general, y todas las secciones de código que tienen sus títulos escritos en letras minúsculas son específicas de nuestro caso práctico.
A continuación se muestra la implementación completa de nuestro primer archivo de python. Los títulos de las secciones de código y los nombres de las variables elegidas son lo suficientemente claros como para comprender lo que se está codificando, pero si necesitas más explicaciones, te recomiendo que vea nuestros videos tutoriales en la plataforma de Frogames Formación donde codificamos todo desde cero, paso a paso, mientras explicamos cada línea. de código en términos de por qué, qué y cómo. Aquí vamos:
# Inteligencia Artificial aplicada a Negocios y Empresas - Caso Práctico 2
# Construcción del Entorno
# Importar las librerías
import numpy as np# CONSTRUCCIÓN DEL ENTORNO EN UNA CLASE
class Environment(object):
# INTRODUCCIÓN E INICIALIZACIÓN DE TODOS LOS PARÁMETROS Y
# VARIABLES DEL ENTORNO
def __init__(self,
optimal_temperature = (18.0, 24.0),
initial_month = 0,
initial_number_users = 10,
initial_rate_data = 60):
self.monthly_atmospheric_temperatures = [1.0, 5.0, 7.0, 10.0, 11.0,
20.0,23.0, 24.0, 22.0, 10.0, 5.0, 1.0]
self.initial_month = initial_month
self.atmospheric_temperature = \
self.monthly_atmospheric_temperatures[initial_month]
self.optimal_temperature = optimal_temperature
self.min_temperature = -20
self.max_temperature = 80
self.min_number_users = 10
self.max_number_users = 100
self.max_update_users = 5
self.min_rate_data = 20
self.max_rate_data = 300
self.max_update_data = 10
self.initial_number_users = initial_number_users
self.current_number_users = initial_number_users
self.initial_rate_data = initial_rate_data
self.current_rate_data = initial_rate_data
self.intrinsic_temperature = self.atmospheric_temperature
+ 1.25 * self.current_number_users
+ 1.25 * self.current_rate_data
self.temperature_ai = self.intrinsic_temperature
self.temperature_noai = (self.optimal_temperature[0]
+ self.optimal_temperature[1]) / 2.0
self.total_energy_ai = 0.0
self.total_energy_noai = 0.0
self.reward = 0.0
self.game_over = 0
self.train = 1 # CREACIÓN DE UN MÉTODO QUE ACTUALIZA EL ENTORNO DESPUÉS
# DE QUE LA IA EJECUTE UNA ACCIÓN
def update_env(self, direction, energy_ai, month):
# OBTENCIÓN DE LA RECOMPENSA
# Calcular la energía gastada por el sistema de refrigeración
# del servidor cuando no hay IA
energy_noai = 0
if (self.temperature_noai < self.optimal_temperature[0]):
energy_noai = self.optimal_temperature[0] - self.temperature_noai
self.temperature_noai = self.optimal_temperature[0]
elif (self.temperature_noai > self.optimal_temperature[1]):
energy_noai = self.temperature_noai - self.optimal_temperature[1]
self.temperature_noai = self.optimal_temperature[1]
# Cálculo de la recompensa
self.reward = energy_noai - energy_ai
# Escalado de la recompensa
self.reward = 1e-3 * self.reward
# OBTENCIÓN DEL SIGUIENTE ESTADO
# Actualización de la temperatura atmosférica
self.atmospheric_temperature =
self.monthly_atmospheric_temperatures[month]
# Actualización del número de usuarios conectados
self.current_number_users += np.random.randint(-self.max_update_users,
self.max_update_users)
if (self.current_number_users > self.max_number_users):
self.current_number_users = self.max_number_users
elif (self.current_number_users < self.min_number_users):
self.current_number_users = self.min_number_users
# Actualización del ratio de datos
self.current_rate_data += np.random.randint(-self.max_update_data,
self.max_update_data)
if (self.current_rate_data > self.max_rate_data):
self.current_rate_data = self.max_rate_data
elif (self.current_rate_data < self.min_rate_data):
self.current_rate_data = self.min_rate_data
# Cálculo de la variación Temperatura Intrinseca
past_intrinsic_temperature = self.intrinsic_temperature
self.intrinsic_temperature = self.atmospheric_temperature
+ 1.25 * self.current_number_users
+ 1.25 * self.current_rate_data
delta_intrinsic_temperature = self.intrinsic_temperature
- past_intrinsic_temperature
# Cálculo de la variación de temperatura causada por la IA
if (direction == -1):
delta_temperature_ai = -energy_ai
elif (direction == 1):
delta_temperature_ai = energy_ai
# Actualización de la temperatura del servidor cuado hay IA
self.temperature_ai += delta_intrinsic_temperature +
delta_temperature_ai
# Actualización de la temperatura del servidor cuado no hay IA
self.temperature_noai += delta_intrinsic_temperature
# OBTENCIÓN DEL FIN DE LA PARTIDA
if (self.temperature_ai < self.min_temperature):
if (self.train == 1):
self.game_over = 1
else:
self.total_energy_ai += self.optimal_temperature[0]
- self.temperature_ai
self.temperature_ai = self.optimal_temperature[0]
elif (self.temperature_ai > self.max_temperature):
if (self.train == 1):
self.game_over = 1
else:
self.total_energy_ai += self.temperature_ai
- self.optimal_temperature[1]
self.temperature_ai = self.optimal_temperature[1]
# ACTUALIZACIÓN DE LOS SCORES
# Actualización del total de energía gastada cuando hay IA
self.total_energy_ai += energy_ai
# Actualización del total de energía gastada cuando no hay IA
self.total_energy_noai += energy_noai
# ESCALADO DEL SIGUIENTE ESTADO
scaled_temperature_ai =
(self.temperature_ai - self.min_temperature) /
(self.max_temperature - self.min_temperature)
scaled_number_users =
(self.current_number_users - self.min_number_users) /
(self.max_number_users - self.min_number_users)
scaled_rate_data =
(self.current_rate_data - self.min_rate_data) /
(self.max_rate_data - self.min_rate_data)
next_state = np.matrix([scaled_temperature_ai,
scaled_number_users,
scaled_rate_data])
# DEVOLVER EL SIGUIENTE ESTADO, LA RECOMPENSA
# Y EL ESTADO DE FIN DEL JUEGO
return next_state, self.reward, self.game_over # CREACIÓN DE UN MÉTODO QUE REINICIA EL ENTORNO
def reset(self, new_month):
self.atmospheric_temperature =
self.monthly_atmospheric_temperatures[new_month]
self.initial_month = new_month
self.current_number_users = self.initial_number_users
self.current_rate_data = self.initial_rate_data
self.intrinsic_temperature = self.atmospheric_temperature
+ 1.25 * self.current_number_users
+ 1.25 * self.current_rate_data
self.temperature_ai = self.intrinsic_temperature
self.temperature_noai = (self.optimal_temperature[0]
+ self.optimal_temperature[1]) / 2.0
self.total_energy_ai = 0.0
self.total_energy_noai = 0.0
self.reward = 0.0
self.game_over = 0
self.train = 1 # CREACIÓN DE UN MÉTODO QUE NOS DA, A PARTIR DE CUALQUIER INSTANTE,
# EL ESTADO, LA RECOMPENSA Y EL FIN DE LA PARTIDA
def observe(self):
scaled_temperature_ai =
(self.temperature_ai - self.min_temperature) /
(self.max_temperature - self.min_temperature)
scaled_number_users =
(self.current_number_users - self.min_number_users) /
(self.max_number_users - self.min_number_users)
scaled_rate_data =
(self.current_rate_data - self.min_rate_data) /
(self.max_rate_data - self.min_rate_data)
current_state = np.matrix([scaled_temperature_ai,
scaled_number_users,
scaled_rate_data])
return current_state, self.reward, self.game_overFelicidades por implementar el Paso 1: Construcción del entorno. Ahora pasemos al Paso 2: Construcción del cerebro.
2.3.2 Paso 2: Construcción del cerebro
En este Paso 2, vamos a construir el cerebro artificial de nuestra IA, que no es más que una red neuronal completamente conectada. Aquí está de nuevo:
El cerebro artificial: una red neuronal completamente conectada
Nuevamente, construiremos este cerebro artificial dentro de una clase, por la misma razón que antes, que nos permite crear varios cerebros artificiales para diferentes servidores dentro de un centro de datos. De hecho, tal vez algunos servidores necesitarán cerebros artificiales diferentes con hiperparámetros diferentes que otros servidores. Es por eso que gracias a esta estructura avanzada de python de clase / objeto, podemos cambiar fácilmente de un cerebro a otro para regular la temperatura de un nuevo servidor que requiere una IA con diferentes parámetros de redes neuronales.
Construiremos este cerebro artificial gracias a la increíble biblioteca Keras. Desde esta librería utilizaremos la clase Dense() para crear nuestras dos capas ocultas completamente conectadas, la primera con 64 neuronas ocultas y la segunda con 32 neuronas. Y luego, utilizaremos la clase Dense() nuevamente para devolver los valores Q, que tienen en cuenta las salidas de las redes neuronales artificiales. Luego, más adelante en el entrenamiento y los archivos de prueba, utilizaremos el método argmax para seleccionar la acción que tenga el valor Q máximo. Luego, ensamblamos todos los componentes del cerebro, incluidas las entradas y las salidas, creándolo como un objeto de la clase Model() (muy útil para luego guardar y cargar un modelo en producción con pesos específicos). Finalmente, lo compilaremos con una función de pérdidas que medirá el error cuadrático medio y el optimizador de Adam. Así, aquí están los nuevos pasos del algoritmo general de IA:
- Paso 2-1: Construir la capa de entrada compuesta de los estados de entrada.
- Paso 2-2: Construir las capas ocultas con un número elegido de estas capas y neuronas dentro de cada una, completamente conectadas a la capa de entrada y entre ellas.
- Paso 2-3: Construir la capa de salida, completamente conectada a la última capa oculta.
- Paso 2-4: Ensamblar la arquitectura completa dentro de un modelo de
Keras. - Paso 2-5: Compilación del modelo con una función de pérdida de error cuadrático medio y el optimizador elegido.
Aquí vamos con la implementación:
# Inteligencia Artificial aplicada a Negocios y Empresas - Caso Práctico 2
# Construcción del cerebro
# Importar las librerías
from keras.layers import Input, Dense
from keras.models import Model
from keras.optimizers import Adam
# CONSTRUCCIÓN DEL CEREBRO
class Brain(object):
# CONSTRUCCIÓN DE UNA RED NEURONAL TOTALMENTE CONECTADA
# EN EL MÉTODO DE INICIALIZACIÓN
def __init__(self, learning_rate = 0.001, number_actions = 5):
self.learning_rate = learning_rate
# CONSTRUCCIÓN DE LA CAPA DE ENTRADA COMPUESTA
# DE LOS ESTADOS DE ETRADA
states = Input(shape = (3,))
# CONSTRUCCIÓN DE LAS DOS CAPAS OCULTAS TOTALMENTE CONECTADAS
x = Dense(units = 64, activation = 'sigmoid')(states)
y = Dense(units = 32, activation = 'sigmoid')(x)
# CONSTRUCCIÓN DE LA CAPA DE SALIDA, TOTALMENTE CONECTADA
# A LA ÚLTIMA CAPA OCULTA
q_values = Dense(units = number_actions, activation = 'softmax')(y)
# ENSAMBLAR LA ARQUITECTURA COMPLETA EN UN MODELO DE KERAS
self.model = Model(inputs = states, outputs = q_values)
# COMPILAR EL MODELO CON LA FUNCIÓN DE PÉRDIDAS DE ERROR CUADRÁTICO
# MEDIO Y EL OPTIMIZADOR ELEGIDO
self.model.compile(loss = 'mse', optimizer = Adam(lr = learning_rate))Dropout.
Hemos pensado que sería valioso para nosotros incluso agregar una técnica más poderosa en nuestro kit de herramientas de IA: el Dropout.
El dropout es una técnica de regularización que evita el sobreajuste. Simplemente consiste en desactivar una cierta proporción de neuronas aleatorias durante cada paso de propagación hacia adelante y hacia atrás. De esa manera, no todas las neuronas aprenden de la misma manera, evitando así que la red neuronal sobreajuste los datos de entrenamiento.
Así es como implementamos el Dropout:
- Primero importamos la función
Dropout:
from keras.layers:from keras.layers import Input, Dense, Dropout- Luego, activamos el Dropout en la primera capa oculta
x, con una proporción de 0.1, lo que significa que el 10% de las neuronas se desactivarán aleatoriamente durante el entrenamiento a cada iteración:
x = Dense(units = 64, activation = 'sigmoid')(states)
x = Dropout(rate = 0.1)(x)- Y finalmente, activamos de nuevo e Dropout en la segunda capa oculta
y, con una proporción de 0.1, lo que significa que eñ 10% de las neuronas se desactivarán aleatoriamente durante el entrenamiento a cada iteración:
y = Dense(units = 32, activation = 'sigmoid')(x)
y = Dropout(rate = 0.1)(y)¡Felicidades! Has implementado el Dropout. Es realmente muy simple, una vez más gracias a Keras.
Debajo está la implementación mejorada del fichero new_brain.py con Dropout incluido:
# Inteligencia Artificial aplicada a Negocios y Empresas - Caso Práctico 2
# Construcción del cerebro
# Importar las librerías
from keras.layers import Input, Dense, Dropout
from keras.models import Model
from keras.optimizers import Adam
# CONSTRUCCIÓN DEL CEREBRO
class Brain(object):
# CONSTRUCCIÓN DE UNA RED NEURONAL TOTALMENTE CONECTADA
#EN EL MÉTODO DE INICIALIZACIÓN
def __init__(self, learning_rate = 0.001, number_actions = 5):
self.learning_rate = learning_rate
# CONSTRUCCIÓN DE LA CAPA DE ENTRADA COMPUESTA
# DE LOS ESTADOS DE ETRADA
states = Input(shape = (3,))
# CONSTRUCCIÓN DE PRIMERA CAPA OCULTAS TOTALMENTE CONECTADA
# CON DROPOUT ACTIVADO
x = Dense(units = 64, activation = 'sigmoid')(states)
x = Dropout(rate = 0.1)(x)
# CONSTRUCCIÓN DE SEGUNDA CAPA OCULTAS TOTALMENTE CONECTADA
# CON DROPOUT ACTIVADO
y = Dense(units = 32, activation = 'sigmoid')(x)
y = Dropout(rate = 0.1)(y)
# CONSTRUCCIÓN DE LA CAPA DE SALIDA, TOTALMENTE CONECTADA
# A LA ÚLTIMA CAPA OCULTA
q_values = Dense(units = number_actions, activation = 'softmax')(y)
# ENSAMBLAR LA ARQUITECTURA COMPLETA EN UN MODELO DE KERAS
self.model = Model(inputs = states, outputs = q_values)
# COMPILAR EL MODELO CON LA FUNCIÓN DE PÉRDIDAS DE ERROR CUADRÁTICO
# MEDIO Y EL OPTIMIZADOR ELEGIDO
self.model.compile(loss = 'mse', optimizer = Adam(lr = learning_rate))Ahora pasemos al siguiente paso de nuestro algoritmo general de IA: Paso 3: Implementación del algoritmo DQN.
2.3.3 Paso 3: Implementación del algoritmo de Deep Reinforcement Learning
En este nuevo archivo de python, simplemente tenemos que seguir el algoritmo Deep Q-Learning que hemos visto anteriormente. Por lo tanto, esta implementación sigue los siguientes subpasos, que forman parte del algoritmo general de IA:
- Paso 3-1: Introducción e inicialización de todos los parámetros y variables del modelo de DQN.
- Paso 3-2: Hacer un método que construya la memoria en Repetición de Experiencia.
- Paso 3-3: Hacer un método que construya y devuelva dos lotes de 10 entradas y 10 objetivos
A continuación se muestra el código que sigue a esta nueva parte del Blueprint de IA:
# Inteligencia Artificial aplicada a Negocios y Empresas - Caso Práctico 2
# Implementar el algoritmo de Deep Q-Learning con Repetición de Experiencia
# Importar las librerías
import numpy as np
# IMPLEMENTAR EL DEEP Q-LEARNING CON REPETICIÓN DE EXPERIENCIA
class DQN(object):
# INTRODUCIR E INICIALIZAR TODOS LOS PARÁMETROS Y VARIABLES DEL DQN
def __init__(self, max_memory = 100, discount = 0.9):
self.memory = list()
self.max_memory = max_memory
self.discount = discount
# CREACIÓN DE UN MÉTODO QUE CONSTRUYA LA MEMORIA DE LA
# REPETICIÓN DE EXPERIENCIA
def remember(self, transition, game_over):
self.memory.append([transition, game_over])
if len(self.memory) > self.max_memory:
del self.memory[0]
# CREACIÓN DEL MÉTODO QUE COSTRUYE DOS LOTES DE ENTRADAS Y OBJETIVOS
def get_batch(self, model, batch_size = 10):
len_memory = len(self.memory)
num_inputs = self.memory[0][0][0].shape[1]
num_outputs = model.output_shape[-1]
inputs = np.zeros((min(len_memory, batch_size), num_inputs))
targets = np.zeros((min(len_memory, batch_size), num_outputs))
for i, idx in enumerate(np.random.randint(0, len_memory,
size = min(len_memory, batch_size))):
current_state, action, reward, next_state = self.memory[idx][0]
game_over = self.memory[idx][1]
inputs[i] = current_state
targets[i] = model.predict(current_state)[0]
Q_sa = np.max(model.predict(next_state)[0])
if game_over:
targets[i, action] = reward
else:
targets[i, action] = reward + self.discount * Q_sa
return inputs, targets2.3.4 Paso 4: Entrenar la IA
Ahora que nuestra IA tiene un cerebro completamente funcional, es hora de entrenarlo. Y esto es exactamente lo que hacemos en este cuarto archivo de python. El proceso es largo, pero muy fácil: comenzamos estableciendo todos los parámetros, luego construimos el entorno creando un objeto de la clase Environment(), luego construimos el cerebro de la IA creando un objeto de la clase Brain(), luego construimos el modelo de Deep Q-Learning creando un objeto de la clase DQN(), y finalmente lanzamos la fase de entrenamiento que conecta todos estos objetos, durante 1000 echos de 5 meses cada uno. Notarás en la fase de entrenamiento de entrenamiento que también exploramos un poco cuando llevamos a cabo las acciones las acciones. Esto consiste en ejecutar algunas acciones aleatorias de vez en cuando. En nuestro Caso Práctico, esto se realizará el 30% de las veces, ya que usamos un parámetro de exploración \(\epsilon = 0.3\), y luego lo forzamos a ejecutar una acción aleatoria al obtener un valor aleatorio entre 0 y 1 que está por debajo de \(\epsilon = 0.3\)). La razón por la que hacemos un poco de exploración es porque mejora el proceso de aprendizaje por refuerzo profundo. Este truco se llama: Exploración vs. Explotación. Luego, además, también veremos que utilizamos una técnica de detención temprana, que se asegurará de detener el entrenamiento si ya no hay una mejora palpable en el rendimiento.
Destaquemos estos nuevos pasos que aún pertenecen a nuestro algoritmo general de IA:
- Paso 4-1: Construcción del entorno creando un objeto de la clase Environment.
- Paso 4-2: Construyendo el cerebro artificial creando un objeto de la clase de Brain
- Paso 4-3: Construyendo el modelo DQN creando un objeto de la clase DQN.
- Paso 4-4: Elección del modo de entrenamiento.
- Paso 4-5: Comenzar el entrenamiento con un bule
fordurante más de 100 epochs de períodos de 5 meses. - Paso 4-6: Durante cada epoch, repetimos todo el proceso de Deep Q-Learning, al tiempo que exploramos el 30% de las veces.
Y ahora implementemos esta nueva parte, Paso 4: Entrenamiento de la IA, de nuestro algoritmo general. A continuación se muestra la implementación completa de este cuarto archivo de python. Una vez más, los títulos de las secciones de código y los nombres de las variables elegidas son lo suficientemente claros como para comprender lo que se programa en cada caso Aquí vamos:
# Inteligencia Artificial aplicada a Negocios y Empresas - Caso Práctico 2
# Entrenamiento de la IA
# Instalación de Keras
# conda install -c conda-forge keras
# Importar las librerías y el resto de ficheros de python
import os
import numpy as np
import random as rn
import environment
import brain
import dqn
# Establecer semillas para la reproducibilidad del experimento
os.environ['PYTHONHASHSEED'] = '0'
np.random.seed(42)
rn.seed(12345)
# CONFIGURACIÓN DE LOS PARÁMETROS
epsilon = .3
number_actions = 5
direction_boundary = (number_actions - 1) / 2
number_epochs = 100
max_memory = 3000
batch_size = 512
temperature_step = 1.5
# CONSTRUCCIÓN DEL ENTORNO CREANDO UN OBJETO DE LA CLASE ENVIRONMENT CLASS
env = environment.Environment(optimal_temperature = (18.0, 24.0),
initial_month = 0,
initial_number_users = 20,
initial_rate_data = 30)
# CONSTRUCCIÓN DEL CEREBRO CREADO UN OBJETO DE LA CLASE BRAIN
brain = brain.Brain(learning_rate = 0.00001, number_actions = number_actions)
# CONSTRUCCIÓN DEL MODELO DE DQN CREANDO UN OBJETO DE LA CLASE DQN
dqn = dqn.DQN(max_memory = max_memory, discount = 0.9)
# ELECCIÓN DEL MODO DE ENTRENAMIENTO
train = True
# Entrenamiento de la IA
env.train = train
model = brain.model
early_stopping = True
patience = 10
best_total_reward = -np.inf
patience_count = 0
if (env.train):
# ARRANCAR EL BUCLE SOBRE TODAS LAS EPOCHS (1 Epoch = 5 Meses)
for epoch in range(1, number_epochs):
# INICIALIZACIÓN DE LAS VARIABLES TANTO DEL ENVIRONMENT
# COMO DEL BUCLE DE ENTRENAMIENTO
total_reward = 0
loss = 0.
new_month = np.random.randint(0, 12)
env.reset(new_month = new_month)
game_over = False
current_state, _, _ = env.observe()
timestep = 0
# EMPEZAR EL BUCLE SOBRE TODOS LOS TIMESTEPS (1 Timestep = 1 Minuto)
# EN UN EPOCH
while ((not game_over) and timestep <= 5 * 30 * 24 * 60):
# EJECUTAR LA SIGUIENTE ACCIÓN POR EXPLORACIÓN
if np.random.rand() <= epsilon:
action = np.random.randint(0, number_actions)
if (action - direction_boundary < 0):
direction = -1
else:
direction = 1
energy_ai = abs(action - direction_boundary) * temperature_step
# EJECUTAR LA SIGUIENTE ACCIÓN POR INFERENCIA
else:
q_values = model.predict(current_state)
action = np.argmax(q_values[0])
if (action - direction_boundary < 0):
direction = -1
else:
direction = 1
energy_ai = abs(action - direction_boundary) * temperature_step
# ACTUALIZACIÓN DEL ENTORNO BUSCANDO EL SIGUIENTE ESTADO
next_state, reward, game_over =
env.update_env(direction, energy_ai,
int(timestep / (30*24*60)))
total_reward += reward
# ALMACENAR LA NUEVA TRANSICIÓN EN LA MEMORIA
dqn.remember([current_state, action, reward, next_state],
game_over)
# REUNIR EN DOS LOTES SEPARADOS LAS ENTRADAS Y LOS OBJETIVOS
inputs, targets = dqn.get_batch(model, batch_size = batch_size)
# CALCULAR LA PÉRDIDA EN LOS DOS LOTES DE ENTRADAS Y OBJETIVOS
loss += model.train_on_batch(inputs, targets)
timestep += 1
current_state = next_state
# IMPRIMIR EL RESULTADO DE ENTREAMIENTO PARA CADA EPOCH
print("\n")
print("Epoch: {:03d}/{:03d}".format(epoch, number_epochs))
print("Energía gastada con AI: {:.0f}".format(env.total_energy_ai))
print("Energía gastada sin AI: {:.0f}".format(env.total_energy_noai))
# EARLY STOPPING
if (early_stopping):
if (total_reward <= best_total_reward):
patience_count += 1
elif (total_reward > best_total_reward):
best_total_reward = total_reward
patience_count = 0
if (patience_count >= patience):
print("Early Stopping")
break
# GUARDAR EL MODELO
model.save("model.h5")Después de ejecutar el código, ya vemos un buen rendimiento de nuestra IA durante el entrenamiento, gastando la mayor parte del tiempo menos energía que el sistema alternativo, es decir, el sistema de enfriamiento integrado del servidor. Pero ese es solo el entrenamiento, ahora necesitamos ver si también obtenemos un buen rendimiento en una nueva simulación de 1 año. Ahí es donde entra en juego nuestro próximo y último archivo de python.
2.3.5 Paso 5: Probar nuestra IA
Ahora, de hecho, tenemos que probar el rendimiento de nuestra IA en una situación completamente nueva. Para hacerlo, ejecutaremos una simulación de 1 año, solo en modo de inferencia, lo que significa que no habrá entrenamiento en ningún momento. Nuestra IA solo devolverá predicciones durante un año completo de simulación. Luego, gracias a nuestro objeto Environment, obtendremos al final la energía total gastada por la IA durante este año completo, así como la energía total gastada por el sistema de enfriamiento integrado del servidor. Eventualmente compararemos estas dos energías totales gastadas, simplemente calculando su diferencia relativa (en %), lo que nos dará exactamente la energía total ahorrada por la IA. ¡Abróchate el cinturón para los ver los resultados finales, que revelaremos al final de esta Parte 2!
En términos de nuestro algoritmo de IA, aquí para la implementación de prueba casi tenemos lo mismo que antes, excepto que esta vez, no tenemos que crear un objeto Brain ni un objeto modelo DQN, y por supuesto no debemos ejecutar el proceso de Deep Q-Learning durante las épocas de entrenamiento. Sin embargo, tenemos que crear un nuevo objeto de Environment, y en lugar de crear un cerebro, cargaremos nuestro cerebro artificial con sus pesos pre-entrenados del entrenamiento anterior que ejecutamos en el Paso 4 - Entrenamiento de la IA. Por lo tanto, demos los subpasos finales de esta parte final del algoritmo de IA:
- Paso 5-1: Construcción de un nuevo entorno creando un objeto de la clase Environment.
- Paso 5-2: Carga del cerebro artificial con sus pesos pre-entrenados del entrenamiento anterior.
- Paso 5-3: Elección del modo de inferencia.
- Paso 5-4: Iniciación de la simulación de 1 año.
- Paso 5-5: En cada iteración (cada minuto), nuestra IA solo ejecuta la acción que resulta de su predicción, y no se lleva a cabo ninguna exploración o entrenamiento de Deep Q-Learning.
Y ahora implementemos esta quinta y última parte, Paso 5: Prueba de la IA. Una vez más, a continuación se muestra la implementación completa de nuestro último archivo de Python. Los títulos de las secciones de código y los nombres de las variables elegidas son lo suficientemente claros como para comprender lo que se está programando, pero si necesitas más explicaciones, te recomiendo que veas nuestros videos tutoriales en Frogames Formación donde programamos todo desde cero, paso a paso, mientras explicamos cada línea de código en términos de por qué, qué y cómo. Aquí vamos:
# Inteligencia Artificial aplicada a Negocios y Empresas - Caso Práctico 2
# Prueba de la AI
# Instalación de Keras
# conda install -c conda-forge keras
# Importar las librerías y el resto de ficheros de python
import os
import numpy as np
import random as rn
from keras.models import load_model
import environment
# Establecer semillas para la reproducibilidad del experimento
os.environ['PYTHONHASHSEED'] = '0'
np.random.seed(42)
rn.seed(12345)
# CONFIGURACIÓN DE LOS PARÁMETROS
number_actions = 5
direction_boundary = (number_actions - 1) / 2
temperature_step = 1.5
# CONSTRUCCIÓN DEL ENTORNO CREANDO UN OBJETO DE LA CLASE ENVIRONMENT
env = environment.Environment(optimal_temperature = (18.0, 24.0),
initial_month = 0,
initial_number_users = 20,
initial_rate_data = 30)
# CARGA DEL MODELO PRE-ENTRENADO
model = load_model("model.h5")
# ELECCIÓN DEL MODO
train = False
# EJECUTAR UN AÑO DE SIMULACIÓN EN MODO INFERENCIA
env.train = train
current_state, _, _ = env.observe()
for timestep in range(0, 12 * 30 * 24 * 60):
q_values = model.predict(current_state)
action = np.argmax(q_values[0])
if (action - direction_boundary < 0):
direction = -1
else:
direction = 1
energy_ai = abs(action - direction_boundary) * temperature_step
next_state, reward, game_over = env.update_env(direction,
energy_ai,
int(timestep / (30*24*60)))
current_state = next_state
# IMPRIMIR LOS RESULTADOS DE ENTREAMIENTO PARA CADA EPOCH
print("\n")
print("Energía gastada con AI: {:.0f}".format(env.total_energy_ai))
print("Energía gastada con AI: {:.0f}".format(env.total_energy_noai))
print("AHORRO DE ENERGÍA: {:.0f} %".
format((env.total_energy_noai - env.total_energy_ai)
/ env.total_energy_noai * 100))Y finalmente, obtenemos en los resultados impresos que el consumo total de energía ahorrado por la IA es …:
\[\textrm{Total Energy saved by the AI} = 39 \ \% \ !\]
¡Exactamente igual a lo que la DeepMind de Google logró en 2016! De hecho, si en Google escribes: DeepMind reduce la factura de enfriamiento de Google, verá que el resultado que lograron es del 40 %. Muy cerca de la nuestra!
Por lo tanto, lo que hemos construido es seguramente excelente para nuestro cliente comercial, ya que nuestra IA les ahorrará muchos costes. De hecho, recuerda que gracias a nuestra estructura orientada a objetos (trabajando con clases y objetos), podemos tomar fácilmente nuestros objetos creados en esta implementación que hicimos para un servidor, y luego conectarlos a otros servidores, para que al final podamos ¡terminar ahorrando en el consumo total de energía de un centro de datos al completo! Así es como Google ahorró miles de millones de dólares en costes relacionados con la energía, gracias a su modelo DQN creado por la IA DeepMind.
2.4 Resumen: El Algoritmo General de IA
Recapitulemos y proporcionemos el algoritmo completo de IA, para que puedas imprimirlo y ponerlo en tu pared.
Paso 1: Construcción del Entorno
- Paso 1-1: Introducción e inicialización de todos los parámetros y variables del entorno.
- Paso 1-2: Hacer un método que actualice el entorno justo después de que la IA ejecute una acción.
- Paso 1-3: Hacer un método que restablezca el entorno.
- Paso 1-4: hacer un método que nos proporcione en cualquier momento el estado actual, la última recompensa obtenida y si el juego ha terminado.
**Paso 2: Construcción del Cerebro
- Paso 2-1: Construir la capa de entrada compuesta de los estados de entrada.
- Paso 2-2: Construir las capas ocultas con un número elegido de estas capas y neuronas dentro de cada una, completamente conectadas a la capa de entrada y entre ellas.
- Paso 2-3: Construir la capa de salida, completamente conectada a la última capa oculta.
- Paso 2-4: Ensamblar la arquitectura completa dentro de un modelo de
Keras. - Paso 2-5: Compilación del modelo con una función de pérdida de error cuadrático medio y el optimizador elegido.
Paso 3: Implementación del algoritmo de Deep Reinforcement Learning
- Paso 3-1: Introducción e inicialización de todos los parámetros y variables del modelo de DQN.
- Paso 3-2: Hacer un método que construya la memoria en Repetición de Experiencia.
- Paso 3-3: Hacer un método que construya y devuelva dos lotes de 10 entradas y 10 objetivos
Paso 4: Entrenamiento de la IA
- Paso 4-1: Construcción del entorno creando un objeto de la clase Environment.
- Paso 4-2: Construyendo el cerebro artificial creando un objeto de la clase de Brain
- Paso 4-3: Construyendo el modelo DQN creando un objeto de la clase DQN.
- Paso 4-4: Elección del modo de entrenamiento.
- Paso 4-5: Comenzar el entrenamiento con un bule
fordurante más de 100 epochs de períodos de 5 meses.
Paso 5: Probar la IA
- Paso 5-1: Construcción de un nuevo entorno creando un objeto de la clase Environment.
- Paso 5-2: Carga del cerebro artificial con sus pesos pre-entrenados del entrenamiento anterior.
- Paso 5-3: Elección del modo de inferencia.
- Paso 5-4: Iniciación de la simulación de 1 año.
- Paso 5-5: En cada iteración (cada minuto), nuestra IA solo ejecuta la acción que resulta de su predicción, y no se lleva a cabo ninguna exploración o entrenamiento de Deep Q-Learning.